Agentic AI über den gesamten Wirkstoff-Lifecycle, von Discovery bis Scale-up
Agentic AI über MCP verbindet fragmentierte R&D-Daten zu einem System. Beispiel-Pipelines von Discovery über CMC bis Manufacturing, und warum die offene Werkzeugschicht über den eigentlichen Wettbewerbsvorteil entscheidet.
Oliver Kraft
CovaSyn
Das Wichtigste in Kürze
- In vielen R&D-Organisationen verbringen hochbezahlte Wissenschaftler einen großen Teil ihres Tages mit Copy-Paste zwischen Systemen, die nicht miteinander reden.
- Agentic AI über MCP lässt einen Agenten ganze Werkzeug- und Modellketten in einem Workflow durchlaufen, nachvollziehbar, Schritt für Schritt.
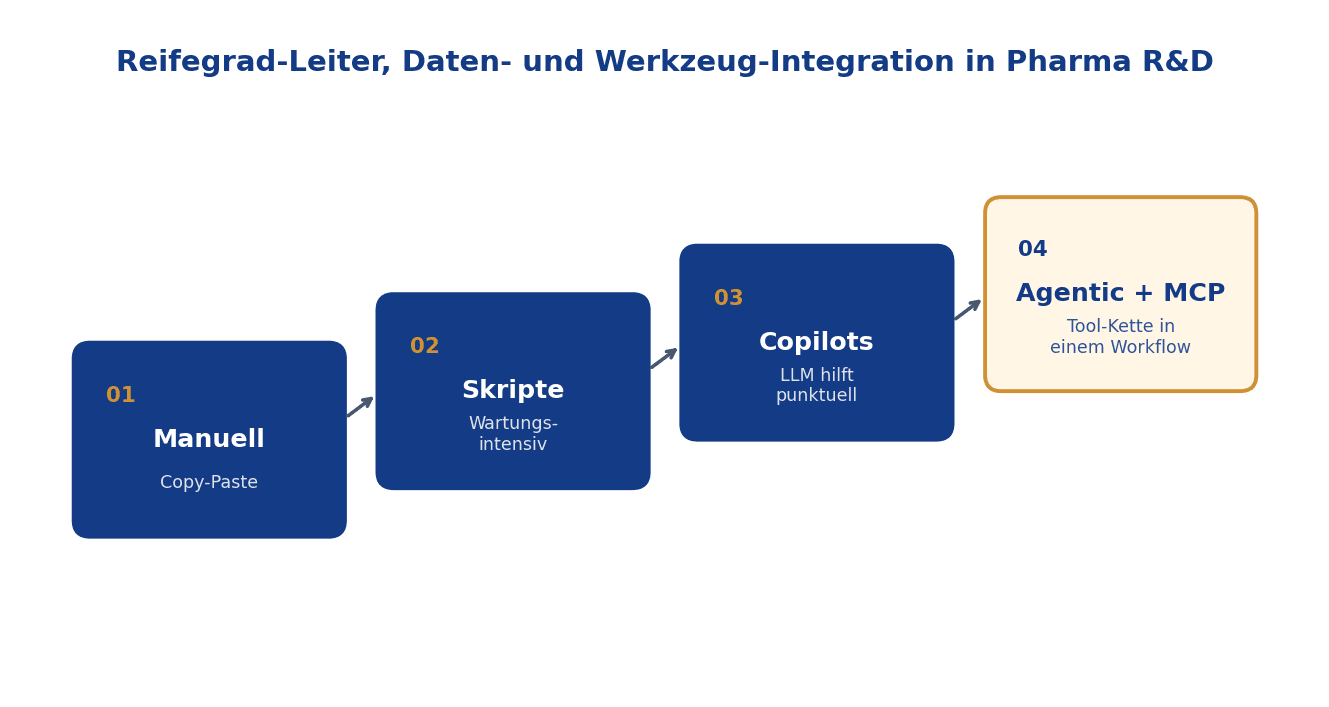
- Der Reifegrad lässt sich auf einer Leiter verorten: Manuell → Skripte → Copilots → Agentic + MCP.
- Beispiel-Pipelines über den ganzen Lifecycle, von Discovery über Entwicklung und CMC bis Manufacturing und Scale-up, wo der Hebel oft am größten und am wenigsten besetzt ist.
- Die Position dazu: eine offene, deterministische Werkzeugschicht, mit der Kunden ihr eigenes LLM auf ihren eigenen Daten nutzen, integrierbar in jeden Workflow.
Die stille Produktivitätssteuer
In fast jeder Pharma-R&D-Organisation gibt es eine Kostenstelle, die in keinem Report auftaucht: hochqualifizierte Wissenschaftler, die einen erheblichen Teil ihrer Zeit damit verbringen, Daten zwischen Systemen hin- und herzukopieren. Die Information liegt in dutzenden getrennten Quellen, Struktur- und Bioaktivitätsdatenbanken, Literatur, interne Messreihen, Analytik, Stabilitätsdaten, und keine spricht mit der anderen.
Eine scheinbar einfache Frage, „Ist diese Verbindung löslich genug, stabil genug und sauber genug, um in die nächste Phase zu gehen?", wird damit zu Tagen manuellen Abfragens, Exportierens und Abgleichens. Bei jedem Hand-off stirbt ein Stück Kontext. Und wenn die Antwort endlich vorliegt, ist die Entscheidung oft schon weitergezogen.
Das ist kein Modell-Problem. Es ist ein Architektur-Problem.
Die Reifegrad-Leiter
Wo ein Team bei der Daten- und Werkzeug-Integration steht, lässt sich auf vier Stufen verorten:
1. Manuell. Wissenschaftler bedienen jedes System von Hand, kopieren Ergebnisse zwischen Tools. Signal: ein Excel-Sheet ist die zentrale Wahrheit, neue Mitarbeiter brauchen Wochen für die Onboarding-Tour durch die Systemlandschaft. 2. Skripte. Wiederkehrende Abfragen sind automatisiert, aber starr und wartungsintensiv, jede neue Quelle bedeutet neuen Code. Signal: ein Python-Repo mit hundert Helper-Skripten, das nur ein Senior-Engineer wirklich versteht. 3. Copilots. Ein LLM hilft bei einzelnen Schritten (Text, Code), bleibt aber vom eigentlichen Werkzeug- und Datenbestand getrennt. Signal: Wissenschaftler tippen Prompts und kopieren das Ergebnis zurück in ihr eigentliches Tool. 4. Agentic + MCP. Ein Agent erreicht über eine standardisierte Schnittstelle (Model Context Protocol) jedes Werkzeug, Modell und jede Datenquelle und führt ganze Ketten in einem Workflow aus. Signal: der Mensch formuliert die Frage, prüft die Antwort, der Agent füllt das Dazwischen mit verifizierbaren Tool-Aufrufen.
Der Sprung von Stufe 3 auf Stufe 4 ist der entscheidende, weil er den Menschen aus der Rolle des manuellen Zusammenstückelns herauslöst, ohne die Nachvollziehbarkeit aufzugeben. Jeder Tool-Aufruf ist ein diskreter, prüfbarer Schritt mit Input, Output und Versions-Stempel.
Warum die Architektur zählt, offen statt geschlossen
An dieser Stelle teilt sich das Feld. Ein Teil der Branche baut geschlossene, vertikal integrierte Engines, eigenes Labor, eigene Modelle, eigene Pipeline, von der Zielstruktur bis zum Kandidaten. Das ist ein mächtiger Ansatz, und Unternehmen wie Recursion oder Isomorphic Labs zeigen, was damit möglich ist.
CovaSyn ist bewusst ein anderer Ansatz, nicht als Konkurrenzbehauptung, sondern als Architektur-Entscheidung. Es ist eine offene, deterministische Werkzeugschicht: die chemischen Modelle und Werkzeuge sind die Bausteine, Kunden nutzen sie mit ihrem eigenen LLM auf ihren eigenen Daten über MCP, in dem Workflow, den sie ohnehin fahren. Daraus ergeben sich drei Eigenschaften, die in einem regulierten Umfeld zählen:
- Validierbar statt Blackbox. Jeder Schritt ist ein deterministischer Tool-Aufruf mit nachprüfbarem Ergebnis, Unsicherheitsintervall und einem Applicability-Domain-Flag, das anzeigt, wann ein Modell extrapoliert.
- Modell-unabhängig statt anbietergebunden. Die Werkzeuge laufen mit dem LLM der Wahl, kein Lock-in an ein einzelnes Foundation-Model. Wer heute Claude nutzt und morgen auf ein hauseigenes Modell wechseln will, behält denselben Tool-Layer.
- Lifecycle-breit statt discovery-eng. Dieselbe Schicht dient Discovery, Lead-Suche, Entwicklung, Prozessoptimierung, Screening und Scale-up. Kein Tool-Wechsel zwischen den Phasen.
Die Stärke sind dabei die Modelle selbst. Bei der Löslichkeitsvorhersage liegt CovaSolv mit R² 0,92 auf einem harten Scaffold-Holdout am oberen Ende des aktuell Publizierten und bringt die Applicability Domain mit, die vielen veröffentlichten Modellen fehlt. Retrosynthese und Toxikologie folgen auf demselben Anspruchsniveau.
Beispiel-Pipelines über den Lifecycle
So sieht eine agentengeführte Kette in der Praxis aus, je Phase eine.
Discovery (Chemicals): Triage einer neuen Serie
In der frühen Phase geht es um Priorisierung: Welche Verbindungen einer Serie verdienen Aufmerksamkeit? Eine Kette könnte lauten: Struktur → Druglikeness/Filter → Löslichkeit → früher Tox-Flag → Priorisierung.
Agent → covabasic_druglikeness(smiles) → Ro5/Veber bestanden
→ covasolve_predict(smiles, "water") → logS −4,2 [−4,5, −3,9]
→ covatox_quickscreen(smiles) → Ames neg., hERG-Risiko niedrig
→ Ergebnis: Kandidat behalten, Löslichkeit als Risiko markiertHier ergänzt CovaSyn die deterministische Berechnungs- und Vorhersageschicht. Wer zusätzlich Target-Bioaktivität oder klinische Signale braucht, föderiert öffentliche Datenquellen dazu, die beiden Schichten ergänzen sich, sie konkurrieren nicht.
Discovery (Biologics / ADC): Developability früh einschätzen
Bei Biologics und Antikörper-Wirkstoff-Konjugaten verschiebt sich die Frage von „bindet es?" zu „lässt es sich entwickeln und herstellen?". Eine Kette über die CovaBio-Suite: Sequenz → biophysikalisches Profil → Aggregations- und Immunogenitäts-Risiko → bei ADC zusätzlich Payload-Eigenschaften und DAR-Abschätzung. Gerade die Payload-Löslichkeit (Exatecan, MMAE und Verwandte) ist ein früher, oft unterschätzter Showstopper, und genau dort liefert die Löslichkeitsschicht eine belastbare Vorhersage statt eines Bauchgefühls.
Development / CMC: eine Kristallisation am Bildschirm auslegen
In der Entwicklung wird aus „interessantem Molekül" ein herstellbarer Prozess. Ein Beispiel, das hier ausführlich dokumentiert ist: die Auslegung einer Kristallisation in drei Schritten. Der Agent bestimmt das Lösungsmittel, rechnet die Ausbeute einer Kühlkristallisation über die Temperaturkurve und prüft, ob ein Anti-Solvent nötig ist. Lösungsmittel, Modus und erwartete Ausbeute stehen, bevor das erste Laborexperiment läuft. Das Ergebnis sind weniger Screening-Läufe und ein de-riskter Prozess.
Manufacturing / Scale-up: Prozessrobustheit vor dem Technikum
Hier liegt der Hebel, über den am wenigsten gesprochen wird, und an dem die Werkzeugschicht besonders stark ist. Beim Übergang vom Labor- in den Produktionsmaßstab entscheidet die Robustheit des Prozessfensters. Eine agentengeführte Kette kann den Designraum vorab ausleuchten:
Agent → covasolve_curve(api, solvent, T-range) → Sättigungskurve & MSZW
→ covasolve_antisolvent(api, antisolvent) → Ausfäll-Profil, Recovery
→ covadoe_create_design(faktoren) → robustes Versuchsdesign
→ covadoe_design_space(...) → ICH-Q8-Designraum, PAR/NOR
→ Ergebnis: belastbares Prozessfenster vor dem ersten TechnikumslaufDazu kommen drei weitere Bausteine, die im CMC- und Manufacturing-Alltag den Unterschied zwischen einem reibungslosen und einem teuren Scale-up ausmachen:
- Stabilitäts- und Shelf-Life-Abschätzung über Arrhenius-Kinetik (CovaStab), inklusive ICH-Q1A-konformer Stress-Schemata. Statt sechs Monate auf reale Daten zu warten, lässt sich der Korridor vorab abschätzen und das tatsächliche Stress-Programm darauf optimieren.
- Impurity-Profiling nach ICH Q3A/Q3B, das verdächtige Verunreinigungen schon im Prozess-Design markiert, bevor sie im Endprodukt zum Audit-Befund werden.
- Mutagenitäts-Triage nach ICH M7 (CovaTox), die jede in-Prozess-Verunreinigung gegen Strukturalert- und QSAR-Modelle prüft und mit Class-1-bis-5-Klassifikation und nachvollziehbarem Audit-Trail dokumentiert.
Statt jeden Punkt experimentell zu erarbeiten, geht das Team mit einem vorausgelegten Designraum ins Technikum. Die Experimente, die dann tatsächlich laufen, sind gezielt gewählt, um die Modell-Vorhersage zu bestätigen oder zu falsifizieren, nicht um den Raum blind zu vermessen. Das ist der Unterschied zwischen drei Wochen iterativem Probieren und vier gezielten Bestätigungsläufen.
Wie der Wechsel von Stufe 3 auf Stufe 4 in der Praxis abläuft
Der Sprung von Copilots zu Agentic + MCP ist konkret machbar, nicht jahrelanges Re-Engineering. Drei pragmatische Schritte:
1. Einen Workflow auswählen, der heute weh tut. Typische Kandidaten: Lösungsmittel-Screening vor Kristallisation, Tox-Triage einer Hit-Liste, Stabilitäts-Bewertung eines Formulierungs-Kandidaten. Klein anfangen, nicht den ganzen Lifecycle auf einmal automatisieren. 2. Den Agenten an die existierenden Werkzeuge hängen. Über MCP braucht der Agent kein neues System, er ruft die Tools auf, die das Team ohnehin kennt. Der Free-Tier macht das in zehn Minuten möglich. 3. Verifizieren statt vertrauen. Jedes Tool-Ergebnis kommt mit Unsicherheitsintervall und Applicability-Domain-Flag. Wenn ein Wert außerhalb der Domäne fällt, geht der Agent zurück und bittet um Lab-Verifikation, statt einfach weiterzurechnen. Das ist die strukturelle Differenz zu einem freistehenden LLM.
Nach zwei bis vier Wochen Iteration steht eine Kette, die einen vorher manuellen Workflow vom Stunden- in den Sekunden-Bereich verschiebt. Ab dort skaliert die Methode auf weitere Workflows, ohne dass die Architektur jedes Mal neu entworfen werden muss.
Ehrlich gesagt, was Agentic AI nicht löst
Drei Punkte, die in jeder Sales-Folie verschwiegen werden:
- Daten-Qualität. Wenn die Quell-Datenbank fehlerhaft ist, repliziert der Agent die Fehler schneller. Das Tool-Layer macht den Workflow effizienter, nicht die zugrundeliegende Wahrheit besser.
- Regulatorische Akzeptanz. Ein FDA- oder EMA-Reviewer akzeptiert noch keinen Agenten-Output blind. Der Agent dokumentiert seine Schritte, aber die finale Validierung und der Submission-Pfad bleiben ein menschlicher Prozess. Der Wert liegt im Vorab-Filtern und im strukturierten Audit-Trail, nicht im Ersatz des Reviews.
- Modell-Grenzen. Wo es keine Trainingsdaten gibt (neue Modalitäten, exotische Lösungsmittel, ungewöhnliche Wirkstoffklassen), liefert auch der beste Agent keine belastbare Antwort. Die Applicability Domain weist explizit darauf hin, das ist Stärke, nicht Schwäche.
Die unbequeme Frage
Der eigentliche Wettbewerbsvorteil entsteht nicht durch das nächste größere Modell, sondern durch den Schritt nach rechts auf der Reifegrad-Leiter, und zwar nicht nur in der Discovery, wo gerade alle hinschauen, sondern über den ganzen Lifecycle, gerade in Entwicklung und Herstellung.
Die Frage für R&D- und Operations-Verantwortliche lautet deshalb: Auf welcher Stufe steht das Team, und in welcher Phase? Wer dieses Jahr von Copilots zu echtem Agentic + MCP wechselt, baut einen Vorsprung auf, der sich schwer zurückkaufen lässt.
Im Free-Tier kannst du die Werkzeugschicht direkt an deinen Agenten hängen und eine erste Kette für deinen eigenen Workflow bauen, 100 Credits pro Woche, keine Kreditkarte. → CovaSyn MCP ansehen
Häufige Fragen
Was ist Agentic AI in der Pharma-Forschung?
Ein Ansatz, bei dem ein AI-Agent nicht nur Text generiert, sondern über eine standardisierte Schnittstelle (MCP) Werkzeuge, Modelle und Datenquellen aufruft und ganze Arbeitsketten eigenständig durchläuft, von der Strukturbewertung bis zur Prozessauslegung, mit nachvollziehbaren Einzelschritten.
Wie hilft das Model Context Protocol in der Wirkstoffentwicklung?
MCP gibt einem Agenten eine einheitliche Art, jede angebundene Datenbank, jedes Tool und jedes Modell zu erreichen. Statt dass ein Mensch Quellen manuell zusammenfügt, läuft die Kette in einem Workflow, schneller und mit durchgängigem Kontext. Mehr zur Architektur: Context Stuffing vs. Tool Calling.
Wo wird AI in der Arzneimittelherstellung eingesetzt?
Zunehmend in Entwicklung und Manufacturing: Auslegung von Kristallisationen, Lösungsmittelauswahl, Prozessrobustheit und Designraum (ICH Q8), Impurity-Profiling und Stabilitäts- und Shelf-Life-Abschätzung. Phasen, in denen gut vorhergesagte Eigenschaften teure Experimente priorisieren.
Ersetzt Agentic AI die Datenbanken und das Labor?
Nein. Sie verbindet vorhandene Datenquellen und Werkzeuge zu einem System und legt Experimente gezielt aus. Die finale Validierung und die Datengenerierung bleiben bei Datenbanken und Labor.
Wie unterscheidet sich Agentic + MCP von einem Copilot wie ChatGPT?
Ein Copilot generiert Text als Antwort. Ein Agent mit MCP ruft konkrete Werkzeuge auf, sammelt deren strukturierte Outputs, kombiniert sie und liefert eine zusammengesetzte Antwort, in der jeder Zwischenschritt nachprüfbar ist. Der Unterschied ist nicht ein besseres Sprachmodell, sondern eine grundlegend andere Architektur. Hintergrund: warum LLMs an Chemie scheitern.
Welche Phase des Lifecycles bekommt am meisten zurück?
Aktuell vermutlich CMC und Manufacturing, weil dort der Stand der Tool-Integration am schwächsten ist und die Hebel (Prozessrobustheit, ICH-Q8-Designraum, Stabilitätsvorhersage) direkt in Kosten und Time-to-Market übersetzen.
Funktioniert das auch mit einem hauseigenen LLM, ohne externe Cloud?
Ja. MCP ist ein offener Standard, das Tool-Layer bindet sich an jedes LLM, das MCP spricht, inklusive selbst gehosteter Open-Weight-Modelle. Für Pharma-Kunden mit strikten Cloud-Restriktionen ist das die strukturell richtige Konfiguration.
CovaSyn MCP
Wissenschaftliche Tools in deinem AI-Workflow.
130+ Funktionen für Pharma, Biotech und Chemie. Free-Tier sofort aktiv.