Agentic AI across the drug-development lifecycle, from discovery to scale-up
Agentic AI over MCP connects fragmented R&D data into one system. Example pipelines from discovery through CMC to manufacturing, and why the open tool layer decides the actual competitive edge.
Oliver Kraft
CovaSyn
TL;DR
- In many R&D organisations, highly-paid scientists spend a large part of their day copy-pasting between systems that do not talk to each other.
- Agentic AI via MCP lets an agent run entire tool and model chains in one workflow, traceable step by step.
- Maturity sits on a ladder: manual → scripts → copilots → agentic + MCP.
- Example pipelines across the lifecycle, from discovery through development and CMC to manufacturing and scale-up, where the lever is often the largest and the least populated.
- The position underneath: an open, deterministic tool layer, used by customers with their own LLM on their own data, integratable into any workflow.
The silent productivity tax
In almost every pharma R&D organisation there is a cost line that shows up in no report: highly-qualified scientists spending a significant share of their time copying data between systems. The information sits in dozens of separate sources, structure and bioactivity databases, literature, internal measurements, analytics, stability data, and none of them speaks to the others.
A seemingly simple question, "is this compound soluble enough, stable enough, clean enough to move to the next phase?", turns into days of manual querying, exporting and reconciling. At every hand-off a piece of context dies. And by the time the answer arrives, the decision has often moved on.
This is not a model problem. It is an architecture problem.
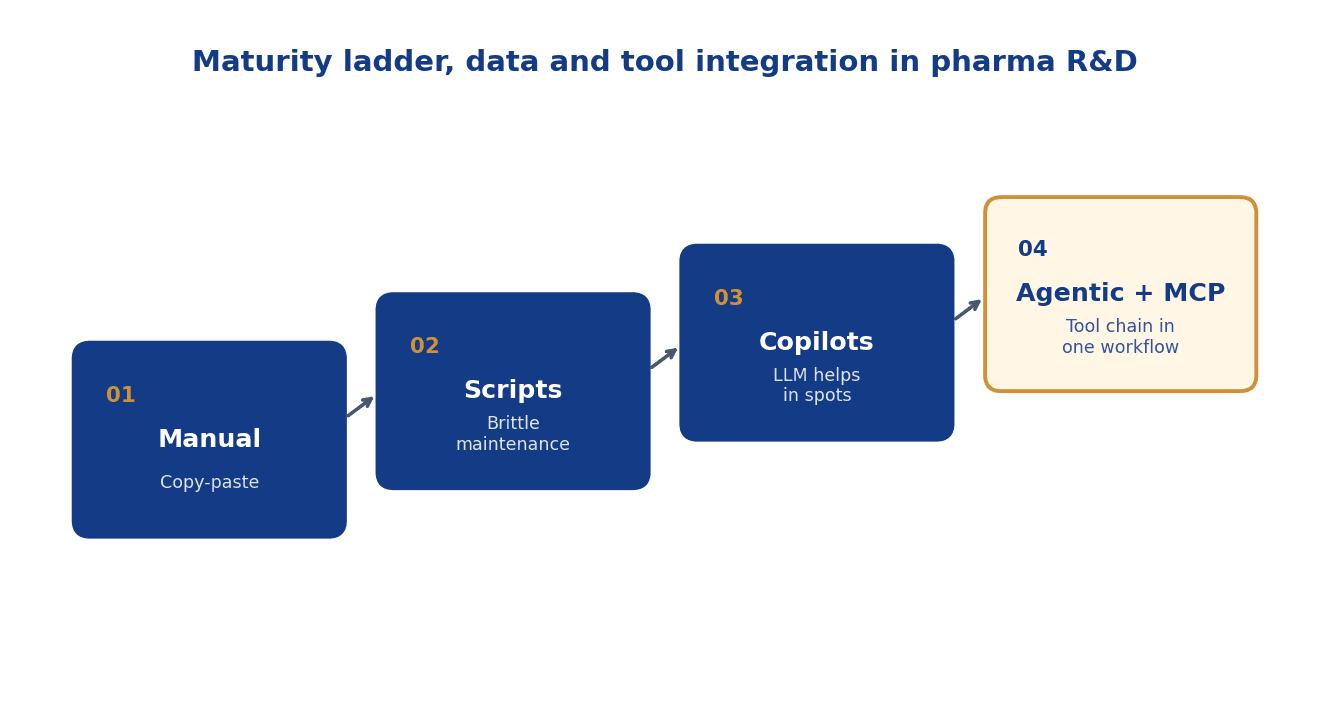
The maturity ladder
Where a team stands on data and tool integration lands on four levels:
1. Manual. Scientists operate each system by hand, copying results between tools. Tell: an Excel sheet is the central truth, new hires need weeks for the onboarding tour through the system landscape. 2. Scripts. Recurring queries are automated, but rigid and maintenance-heavy, every new source means more code. Tell: a Python repo with a hundred helper scripts that only a senior engineer truly understands. 3. Copilots. An LLM helps on single steps (text, code) but stays separated from the actual tool and data stack. Tell: scientists type prompts and paste the result back into their real tool. 4. Agentic + MCP. An agent reaches every tool, model and data source through a standardised interface (Model Context Protocol) and runs whole chains in one workflow. Tell: the human formulates the question, checks the answer, the agent fills the in-between with verifiable tool calls.
The step from level 3 to level 4 is the decisive one because it removes the human from the role of manual stitching, without losing traceability. Every tool call is a discrete, verifiable step with input, output and version stamp.
Why architecture matters, open over closed
The field splits here. Part of the industry is building closed, vertically integrated engines, in-house labs, in-house models, in-house pipeline, from target structure to candidate. That is a powerful approach, and companies like Recursion or Isomorphic Labs show what is possible with it.
CovaSyn is deliberately a different approach, not a competitive claim but an architecture choice. It is an open, deterministic tool layer: the chemistry models and tools are the building blocks, customers use them with their own LLM on their own data via MCP, in the workflow they already run. Three properties fall out of that, properties that matter in a regulated setting:
- Verifiable, not a black box. Every step is a deterministic tool call with verifiable output, uncertainty interval and an applicability-domain flag that signals when a model extrapolates.
- Model-independent, not vendor-locked. The tools run with the LLM of choice, no lock-in to a single foundation model. A team on Claude today that wants to switch to an in-house model tomorrow keeps the same tool layer.
- Lifecycle-wide, not discovery-narrow. The same layer serves discovery, lead finding, development, process optimisation, screening and scale-up. No tool-switch between phases.
The strength underneath is in the models themselves. For solubility prediction CovaSolv sits at R² 0.92 on a hard scaffold holdout at the upper end of what is currently published, and ships an applicability domain that many published models lack. Retrosynthesis and toxicology follow at the same level of ambition.
Example pipelines across the lifecycle
This is what an agent-led chain looks like in practice, one per phase.
Discovery (chemicals): triage a new series
In the early phase the question is prioritisation: which compounds in a series deserve attention? A chain might read: structure → druglikeness/filters → solubility → early tox flag → prioritisation.
Agent → covabasic_druglikeness(smiles) → Ro5/Veber passed
→ covasolve_predict(smiles, "water") → logS −4.2 [−4.5, −3.9]
→ covatox_quickscreen(smiles) → Ames neg., hERG risk low
→ Result: keep the candidate, flag solubility as riskCovaSyn complements this with the deterministic calculation and prediction layer. Teams that also need target bioactivity or clinical signals federate public sources alongside, the two layers complement each other, they do not compete.
Discovery (biologics / ADC): catch developability early
For biologics and antibody-drug conjugates the question shifts from "does it bind?" to "can we develop and manufacture it?". A chain through the CovaBio suite: sequence → biophysical profile → aggregation and immunogenicity risk → for ADC, additional payload properties and DAR estimate. Payload solubility (exatecan, MMAE and relatives) in particular is an early, often underestimated showstopper, and that is where the solubility layer delivers a defensible prediction instead of a hunch.
Development / CMC: design a crystallization at the screen
Development is where "interesting molecule" turns into a manufacturable process. A worked example documented here: designing a crystallization in three steps. The agent picks the solvent, models the yield of a cooling crystallization across the temperature curve, and checks whether an anti-solvent is needed. Solvent, mode and expected yield are set before the first lab experiment runs. Fewer screening runs, a de-risked process.
Manufacturing / scale-up: process robustness before the pilot plant
This is the lever talked about least and where the tool layer is strongest. The robustness of the process window decides the move from lab to production scale. An agent-led chain can map the design space up front:
Agent → covasolve_curve(api, solvent, T-range) → saturation curve & MSZW
→ covasolve_antisolvent(api, antisolvent) → precipitation profile, recovery
→ covadoe_create_design(factors) → robust experimental design
→ covadoe_design_space(...) → ICH Q8 design space, PAR/NOR
→ Result: defensible process window before the first pilot runThree further building blocks make the difference between a smooth and an expensive scale-up in everyday CMC and manufacturing work:
- Stability and shelf-life estimation through Arrhenius kinetics (CovaStab), including ICH-Q1A-aligned stress schemes. Instead of waiting six months for real data, the band can be estimated up front and the actual stress programme optimised against it.
- Impurity profiling along ICH Q3A/Q3B, which flags suspect impurities in the process design before they become audit findings in the final product.
- Mutagenic-impurity triage along ICH M7 (CovaTox), which evaluates every in-process impurity against structural-alert and QSAR models and documents a Class-1-to-5 classification with a traceable audit trail.
Instead of working out every point experimentally, the team walks into the pilot plant with a pre-designed space. The experiments that then actually run are chosen to confirm or falsify the model prediction, not to map the space blind. That is the difference between three weeks of iterative trial and four targeted confirmation runs.
How a level-3-to-level-4 move actually unfolds
The jump from copilots to agentic + MCP is concrete and doable, not years of re-engineering. Three pragmatic steps:
1. Pick a workflow that hurts today. Typical candidates: solvent screening before crystallization, tox triage on a hit list, stability assessment of a formulation candidate. Start small, do not automate the whole lifecycle in one go. 2. Hook the agent into the existing tools. Through MCP the agent needs no new system, it calls the tools the team already knows. The free tier makes this possible in ten minutes. 3. Verify, do not trust. Every tool result ships with an uncertainty interval and an applicability-domain flag. When a value falls outside the domain, the agent reaches back and asks for lab confirmation instead of carrying on regardless. That is the structural difference to a standalone LLM.
After two to four weeks of iteration, a chain stands that pulls a previously manual workflow from hours into seconds. From there the method scales to more workflows, without redesigning the architecture each time.
Honestly, what agentic AI does not solve
Three points that get glossed over in every sales deck:
- Data quality. If the source database is wrong, the agent replicates the errors faster. The tool layer makes the workflow more efficient, not the underlying truth more accurate.
- Regulatory acceptance. An FDA or EMA reviewer does not yet take agent output on faith. The agent documents its steps, but the final validation and the submission path remain a human process. The value is in upstream filtering and a structured audit trail, not in replacing the review.
- Model boundaries. Where training data does not exist (new modalities, exotic solvents, unusual compound classes) even the best agent does not deliver a defensible answer. The applicability domain calls that out explicitly, which is a strength, not a weakness.
The uncomfortable question
The actual competitive edge does not come from the next bigger model, it comes from stepping right on the maturity ladder, and not only in discovery, where everyone is currently looking, but across the lifecycle, especially in development and manufacturing.
The question for R&D and operations leaders is therefore: what level is the team on, and in which phase? Whoever moves from copilots to real agentic + MCP this year builds a head start that is hard to buy back.
The free tier lets you hook the tool layer straight into your agent and build a first chain for your own workflow, 100 credits per week, no credit card. → See CovaSyn MCP
FAQ
What is agentic AI in pharma research?
An approach where an AI agent does not just generate text, it calls tools, models and data sources through a standardised interface (MCP) and runs whole work chains on its own, from structure assessment to process design, with traceable intermediate steps.
How does the Model Context Protocol help in drug development?
MCP gives an agent a uniform way to reach any connected database, tool or model. Instead of a human stitching sources by hand, the chain runs in one workflow, faster and with continuous context. More on the architecture: context stuffing vs tool calling.
Where is AI used in drug manufacturing?
Increasingly in development and manufacturing: crystallization design, solvent selection, process robustness and design space (ICH Q8), impurity profiling and stability/shelf-life estimation. Phases where well-predicted properties prioritise expensive experiments.
Does agentic AI replace the databases and the lab?
No. It connects existing data sources and tools into one system and lays out experiments deliberately. Final validation and data generation stay with the databases and the lab.
How is agentic + MCP different from a copilot like ChatGPT?
A copilot generates text as the answer. An agent with MCP calls concrete tools, collects their structured outputs, combines them and returns a composed answer in which every intermediate step is verifiable. The difference is not a better language model, it is a fundamentally different architecture. Background: why LLMs fail at chemistry.
Which lifecycle phase gets the most back?
Probably CMC and manufacturing today, because tool integration there is the weakest and the levers (process robustness, ICH Q8 design space, stability prediction) translate directly into cost and time-to-market.
Does this work with an in-house LLM, without external cloud?
Yes. MCP is an open standard, the tool layer binds to any LLM that speaks MCP, including self-hosted open-weight models. For pharma customers with strict cloud restrictions, this is the structurally right configuration.
CovaSyn MCP
Scientific tools in your AI workflow.
130+ functions for pharma, biotech and chemistry. Free tier instantly active.