CovaSolv im Benchmark: Löslichkeit mit R² 0,92 vorhersagen, und warum die ehrliche Zahl die wichtigere ist
CovaSolv sagt logS mit R² 0,92 und RMSE 0,64 voraus, auf 5.315 ungesehenen Molekülgerüsten. 78 % aller Vorhersagen liegen innerhalb von 0,5 log-Einheiten vom Messwert. Wie nah das an der physikalischen Messgrenze liegt, ehrlich erklärt.
Oliver Kraft
CovaSyn

Das Wichtigste in Kürze
- CovaSolv sagt die Löslichkeit (log S) mit R² 0,92, RMSE 0,64 log voraus; 78 % aller Vorhersagen liegen innerhalb von 0,5 log-Einheiten vom Messwert.
- Diese Zahl stammt von einem Scaffold-Holdout: getestet auf 5.315 Molekülgerüsten, die das Modell nie gesehen hat, nicht von einem geschönten Random-Split.
- Das liegt praktisch an der physikalischen Messgrenze: die Reproduzierbarkeit experimenteller Löslichkeit zwischen Laboren beträgt rund 0,6 log.
- CovaSolv schlägt die klassische ESOL-Gleichung klar (RMSE 0,69 vs. 0,96; R² 0,91 vs. 0,55) und ist konkurrenzfähig bis besser als aktuelle ML-Modelle.
- Jede Vorhersage kommt mit kalibriertem Unsicherheitsintervall und einem Applicability-Domain-Flag, das Modell sagt selbst, wann es extrapoliert.
Die Zahl zuerst
Löslichkeit ist eine der frühesten und folgenreichsten Eigenschaften in der Wirkstoffentwicklung. Sie entscheidet über Bioverfügbarkeit, über Formulierbarkeit und über die Lösungsmittelwahl in jedem Kristallisations- und Aufreinigungsschritt. Und sie ist notorisch schwer vorherzusagen.
CovaSolv, das Löslichkeitsmodul der CovaSyn-Plattform, sagt den dekadischen Logarithmus der Löslichkeit (log S, in mol/L) mit folgender Genauigkeit voraus:
- R² = 0,920
- RMSE = 0,636 log
- MAE = 0,371 log
- 78,0 % der Vorhersagen innerhalb von 0,5 log
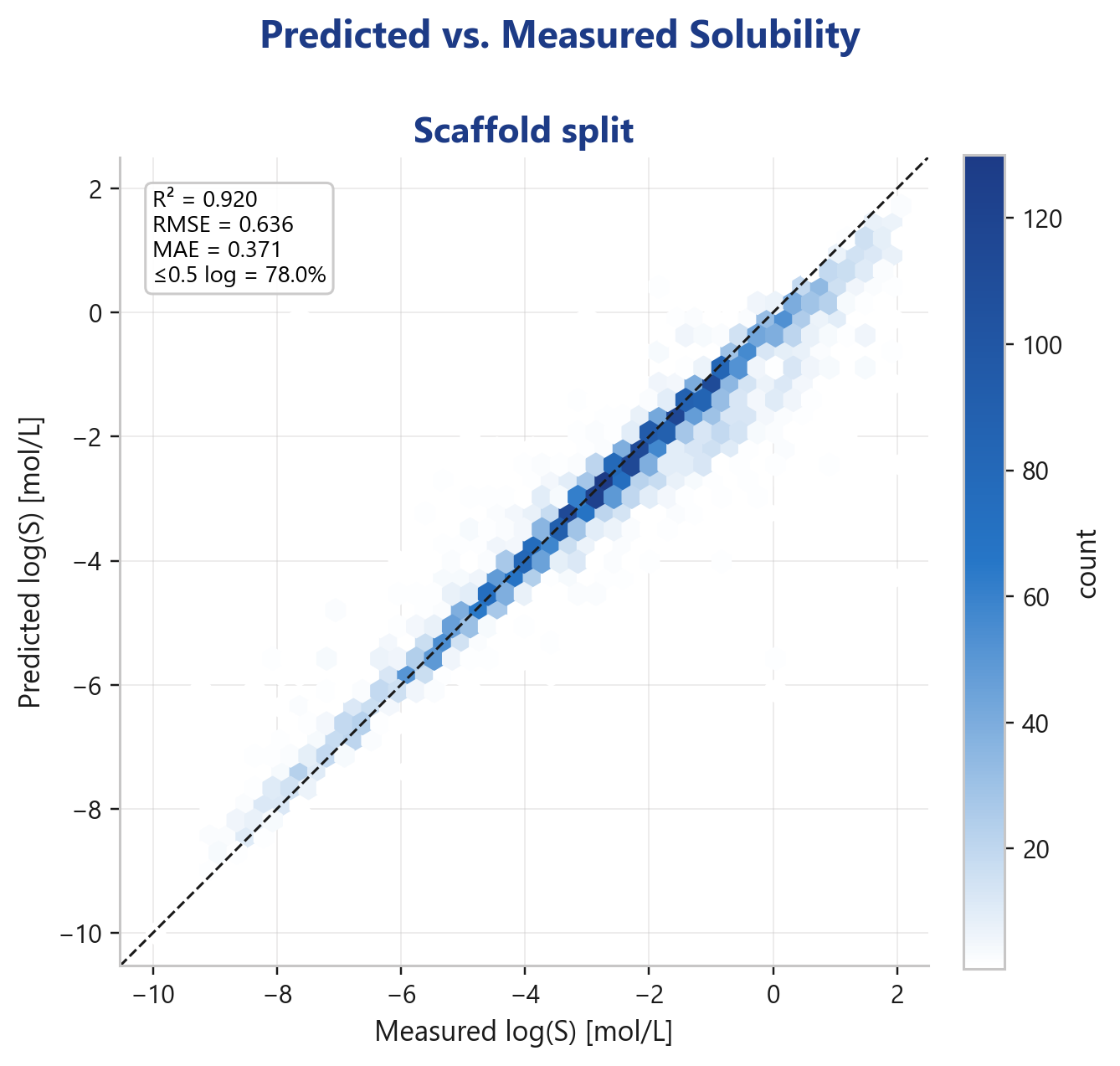
Im Parity-Plot legen sich die Vorhersagen eng an die Diagonale, über einen Bereich von mehr als zehn log-Einheiten. Wichtig: Das ist das eingesetzte Produktionsmodell, ausgewertet auf zurückgehaltenen Daten, keine Trainings-Metrik, die man sich selbst schönrechnet.
Aber wie ehrlich ist diese Zahl?
Hier wird es interessant, denn bei Löslichkeits-Benchmarks steckt der Teufel in der Test-Methodik.
Der bequeme Weg ist ein Random-Split: Man mischt alle Moleküle, nimmt 80 % zum Trainieren und 20 % zum Testen. Das Problem: Eng verwandte Analoga desselben Molekülgerüsts landen dann in beiden Töpfen. Das Modell hat im Training quasi schon "über die Schulter geschaut" und sieht im Test alte Bekannte. Die Zahlen sehen großartig aus, und kollabieren, sobald in der echten Forschung ein wirklich neues Gerüst auftaucht.
Wir testen deshalb per Scaffold-Holdout: Ganze Molekülgerüste werden komplett aus dem Training entfernt und nur im Test gezeigt. Das Modell muss auf strukturell neuen Klassen generalisieren, genau die Situation, die in der Medizinalchemie täglich vorkommt. Es ist die harte, ehrliche Metrik, und genau auf ihr erreicht CovaSolv die R²-0,92-Zahl.
Kurz gesagt: Wir berichten die schwierige Zahl, nicht die einfache.
CovaSolv arbeitet an der physikalischen Messgrenze
Die zweite Frage, die man stellen muss: Wie viel besser kann ein Modell überhaupt werden?
Die Antwort ist physikalisch begrenzt. Misst man dieselbe Verbindung in verschiedenen Laboren, streuen die Ergebnisse: Die publizierte Inter-Labor-Reproduzierbarkeit experimenteller Löslichkeit liegt bei rund 0,6 log-Einheiten. Das ist das Grundrauschen der Realdaten selbst, kein Modell kann konsistenter sein als die Daten, auf denen es trainiert und gegen die es gemessen wird.
CovaSolvs RMSE von 0,64 bis 0,69 log liegt damit praktisch auf dieser Rauschgrenze. Auf breiten, diversen Realdaten ist mehr kaum mehr messbar, die verbleibende Differenz verschwindet im experimentellen Rauschen. Das ist eine starke Aussage, und sie ist ehrlich: Näher dran geht physikalisch fast nicht.
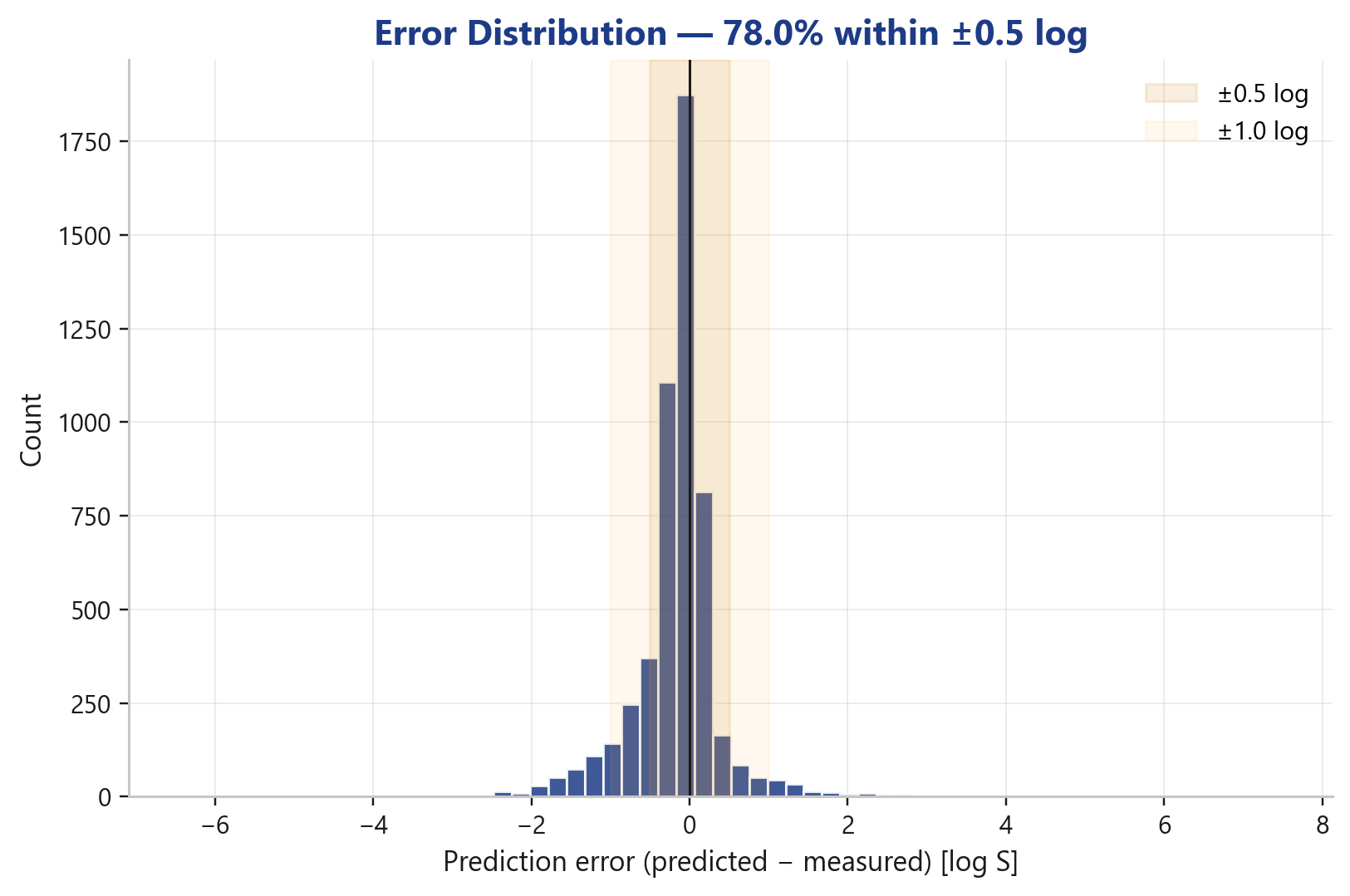
Die Fehlerverteilung zeigt das anschaulich: ein scharfer, symmetrischer Peak um null, kein systematischer Bias, dünn auslaufende Flanken. Der Großteil der Vorhersagen sitzt im ±0,5-log-Band, der weit überwiegende Rest im ±1,0-log-Band.
Im Vergleich zur Literatur
Eine Zahl allein sagt wenig, sie braucht Kontext. Der etablierte Referenzpunkt für wässrige Löslichkeit ist die ESOL-Gleichung (Delaney 2004), bis heute eine vielzitierte Baseline.
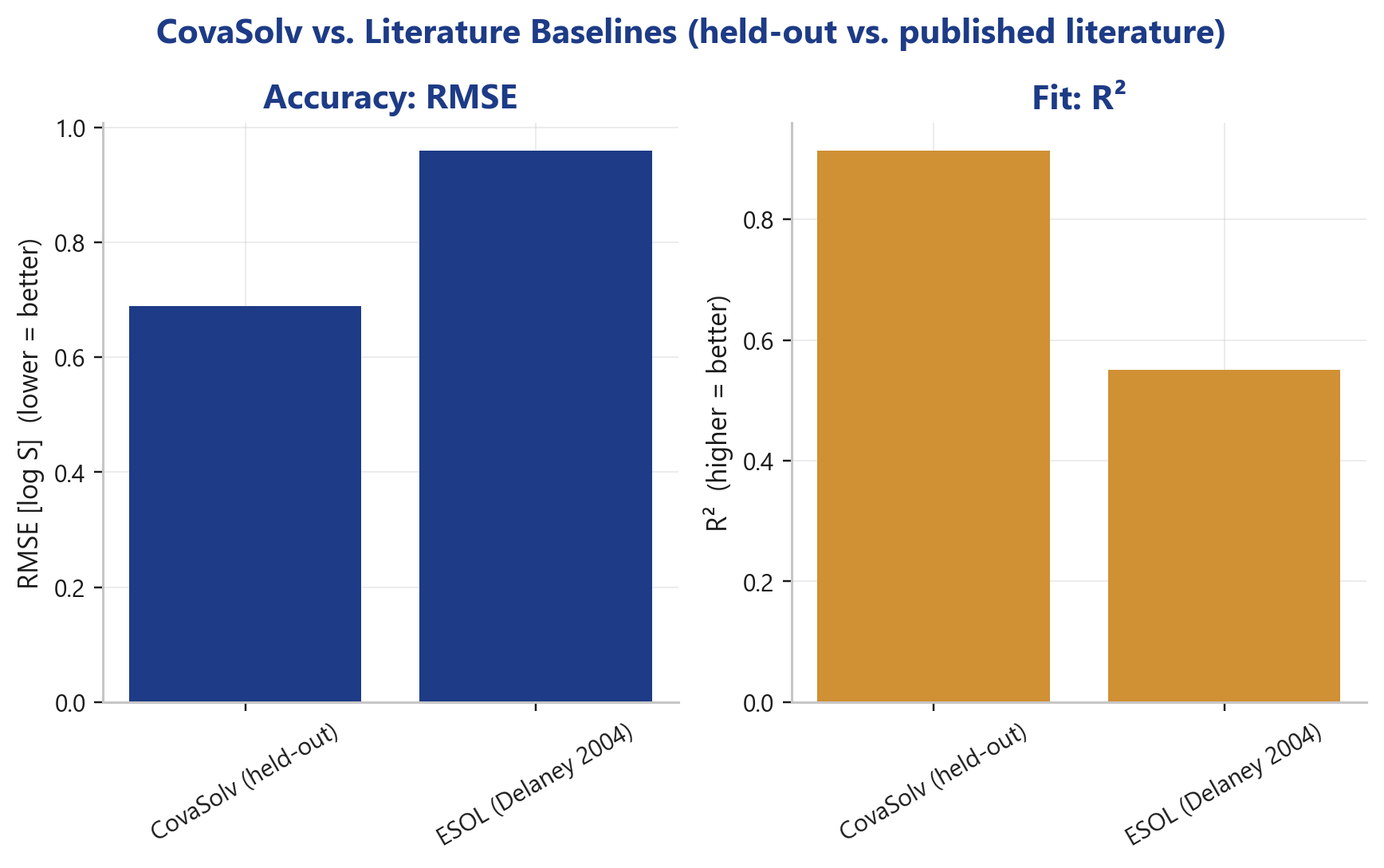
- CovaSolv (held-out, wässrig): RMSE 0,69 · R² 0,91
- ESOL (Delaney 2004): RMSE 0,96 · R² 0,55
CovaSolv senkt den Fehler deutlich und nahezu verdoppelt die erklärte Varianz. Zum Einordnen gegenüber neueren ML-Ansätzen (publizierte Werte): ein 2025er-LightGBM-Modell liegt bei RMSE ≈ 0,85, ein SolTranNet-Transformer bei ≈ 1,46, und der Durchschnitt der Solubility-Challenge-Teilnehmer bei ≈ 1,14.
Ein Fairness-Hinweis, der dazugehört:
Diese Literaturwerte stammen von unterschiedlichen Test-Sets. Ein direkter Zahlenvergleich überzeichnet daher tendenziell, wer ein anderes Test-Set nutzt, misst eine andere Aufgabe. Wir sagen das offen, statt es zu verschweigen. Und für die ESOL-Gegenüberstellung verwenden wir bewusst das wässrige Held-out-Subset von CovaSolv (RMSE 0,69), weil ESOL ein reines Wasser-Modell ist, ein Vergleich auf gemischten Lösungsmitteln wäre unfair zugunsten von CovaSolv.
Das Modell kennt seine Grenzen
Ein Punktwert ohne Kontext ist in der Forschung gefährlich. Die eigentlich wertvolle Eigenschaft eines Vorhersagemodells ist nicht nur, was es sagt, sondern wie sicher es sich ist.
CovaSolv liefert zwei Vertrauensschichten mit:
- Applicability-Domain-Flag. Das Modell markiert selbst, wenn eine Anfrage außerhalb des chemischen Raums liegt, den es zuverlässig abdeckt, etwa bei sehr großen oder strukturell neuartigen Molekülen. Statt einer überzeugend klingenden, aber unbelegten Zahl bekommt man eine ehrliche Warnung.
- Conformal-Vorhersageintervalle. Jede Vorhersage kommt mit einem kalibrierten Unsicherheitsintervall, kein blindes Punkt-Ergebnis, sondern eine quantifizierte Spanne, mit der ein Wissenschaftler tatsächlich Risiko abwägen kann.
Die Botschaft: Ein Modell, dem man vertrauen kann, weil es sagt, wann man ihm vertrauen kann.
Verifizierbar an bekannten Wirkstoffen
Vertrauen entsteht durch Nachprüfbarkeit. Deshalb hier die Vorhersagen für gängige, gut vermessene Wirkstoffe gegen ihre experimentellen Werte, jeder kann gegenchecken:
- Aspirin: vorhergesagt −1,61 · experimentell −1,72 · absoluter Fehler 0,11
- Paracetamol: vorhergesagt −1,14 · experimentell −1,03 · Fehler 0,11
- Benzoesäure: vorhergesagt −1,32 · experimentell −1,55 · Fehler 0,23
- Lidocain: vorhergesagt −1,94 · experimentell −1,70 · Fehler 0,24
- Ibuprofen: vorhergesagt −3,94 · experimentell −3,62 · Fehler 0,32
- Caffein: vorhergesagt −0,98 · experimentell −0,60 · Fehler 0,38
- Carbamazepin: vorhergesagt −3,50 · experimentell −3,01 · Fehler 0,49
- Salicylsäure: vorhergesagt −1,37 · experimentell −1,94 · Fehler 0,57
- Naproxen: vorhergesagt −3,54 · experimentell −4,21 · Fehler 0,67
Die meisten Fehler liegen klar unter 0,5 log, und selbst die größeren bewegen sich in der Größenordnung des experimentellen Rauschens.
Reicht bis zu modernen, komplexen Molekülen
Klassische Modelle wurden auf einfachen, kleinen Molekülen trainiert und scheitern an der heutigen Pharma-Realität. CovaSolv liefert Vorhersagen, inklusive Unsicherheit und AD-Flag, bis hinein in aktuelle, schwierige Strukturen:
- Osimertinib: −3,24 log S · 90 %-Intervall [−3,4; −3,0] · in domain
- Nirmatrelvir: −2,58 · [−3,1; −2,0] · in domain
- Sotorasib: −4,25 · [−4,5; −4,0] · in domain
- Exatecan: −3,29 · [−3,3; −3,2] · in domain
- Deruxtecan: −2,43 · [−3,5; −1,4] · in domain
- MMAE: −3,14 · [−3,4; −2,8] · in domain
Bemerkenswert: Auch ADC-Payloads wie Exatecan, Deruxtecan und MMAE, Strukturen, an denen einfache Modelle reihenweise versagen, bleiben innerhalb der Domain. Wo das Intervall breiter wird (Deruxtecan), kommuniziert das Modell die größere Unsicherheit ehrlich mit, statt sie zu verstecken.
Nicht nur eine Zahl, praktischer Nutzen
Eine gute log-S-Zahl ist Mittel zum Zweck. Im Labor und in der Prozessentwicklung zählt, was man damit tut. CovaSolv beantwortet die Fragen, die im Workflow tatsächlich gestellt werden.
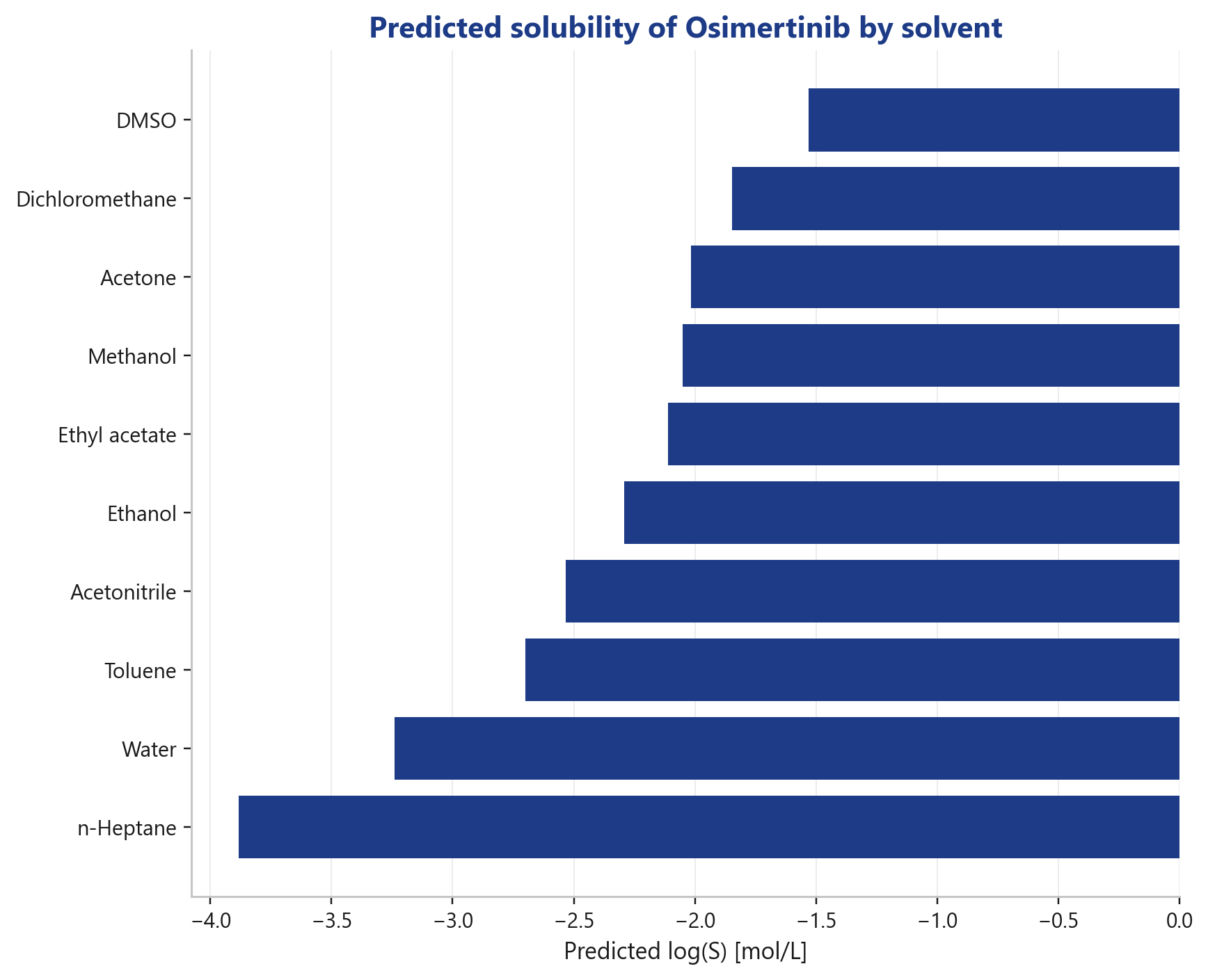
Welches Lösungsmittel löst meine Verbindung am besten?
Ein Solvent-Ranking über gängige Prozesslösungsmittel, am Beispiel Osimertinib reicht die vorhergesagte Löslichkeit von DMSO (am besten) bis n-Heptan (am schlechtesten).
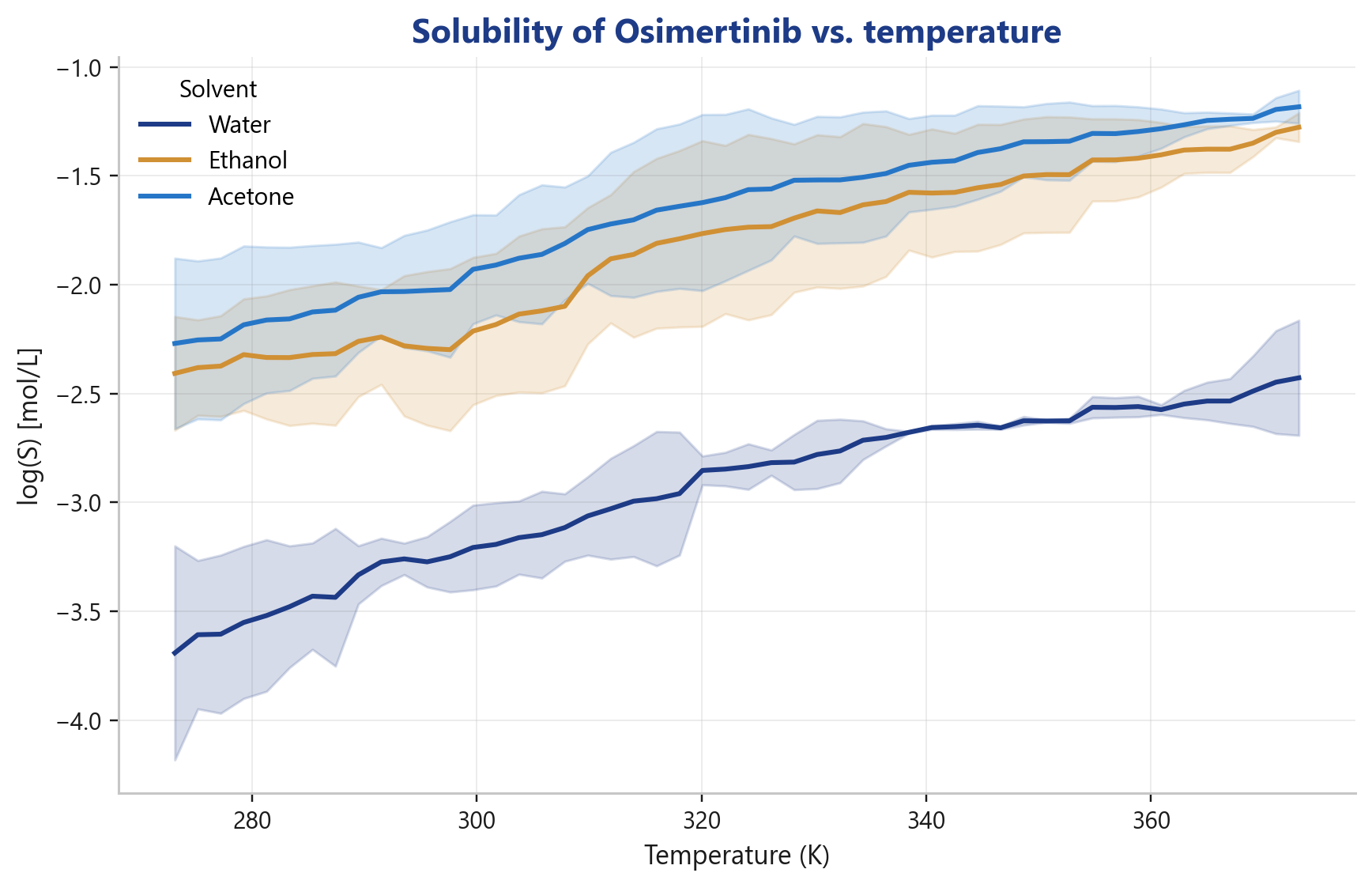
Wie verhält sich die Löslichkeit über Temperatur?
Die Temperaturkurven inklusive Unsicherheitsband liefern die Grundlage für die Auslegung von Kühlkristallisationen.
Und in einem Lösungsmittelgemisch?
Die Löslichkeitslandschaft über Temperatur × Ethanol-Anteil zeigt das Optimum auf einen Blick, der Startpunkt für Anti-Solvent- und Kühlkristallisations-Strategien in der Prozessentwicklung.
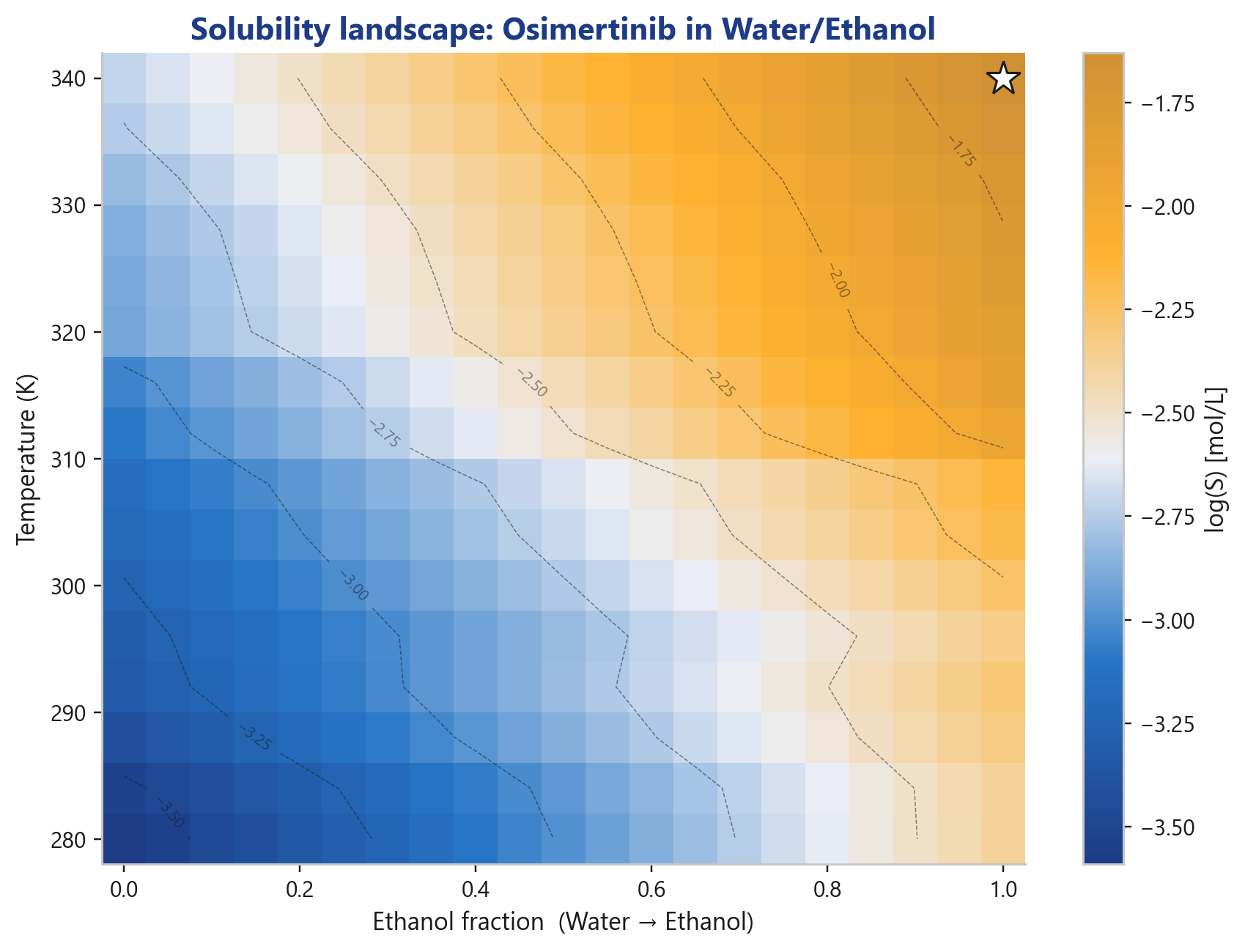
Das ist der Übergang von "interessante Vorhersage" zu "brauchbare Prozessentscheidung", und genau dort liegt der Wert im CMC- und Präformulierungs-Alltag.
Die Datenbasis
Belastbare Zahlen brauchen belastbare Daten. CovaSolv ist auf 95.633 Löslichkeitsmessungen trainiert (aus BigSolDB v2.0 und OChem), nutzt 339 ausgewählte molekulare Features und basiert auf einem XGBoost/LightGBM-Ensemble. Die Architektur ist bewusst klassisch und robust statt experimentell, weil Reproduzierbarkeit in regulierten Workflows mehr zählt als Neuheit um ihrer selbst willen.
Warum Löslichkeitsvorhersage schwer ist, und warum naive Benchmarks täuschen
Zum Schluss der ehrliche Kontext, der diese Zahlen erst einordnet.
Löslichkeit ist aus drei Gründen hart: Erstens das experimentelle Rauschen (die erwähnten ~0,6 log). Zweitens der Unterschied zwischen apparenter und intrinsischer Löslichkeit, gemessene Werte hängen von Festkörperform, Polymorphie und Versuchsbedingungen ab. Drittens die Ionisierung: pH und pKa verschieben die scheinbare Löslichkeit um Größenordnungen.
Und der wichtigste Grund, bei Benchmark-Vergleichen vorsichtig zu sein: Trainings-Overlap (Leakage). Öffentliche Challenge-Sets überschneiden sich teils mit den großen Trainingsdatenbanken. Ein Modell, das einen Teil des "Test"-Sets bereits im Training gesehen hat, berichtet glänzende, aber bedeutungslose Zahlen. Genau deshalb testen wir per Scaffold-Holdout und weisen Test-Set-Unterschiede explizit aus.
Wir publizieren das offen, weil eine glaubwürdige Zahl mehr wert ist als eine beeindruckende. Die vollständige Methodik und alle Roh-Metriken stehen unter covasyn.com/benchmark.
Selbst nachvollziehen
Im Free-Tier kannst du CovaSolv direkt an deinen AI-Agenten hängen, Claude, ChatGPT, Cursor oder Copilot, und log-S-Vorhersagen, Solvent-Rankings und Temperaturkurven für deine eigenen Strukturen abfragen. 100 Credits pro Woche, keine Kreditkarte. → CovaSyn MCP ansehen
Häufige Fragen
Wie genau ist KI-Löslichkeitsvorhersage?
CovaSolv erreicht R² 0,92 und RMSE 0,64 log auf einem Scaffold-Holdout von 5.315 ungesehenen Molekülgerüsten; 78 % der Vorhersagen liegen innerhalb von 0,5 log. Das liegt nahe an der physikalischen Messgrenze von rund 0,6 log Inter-Labor-Reproduzierbarkeit.
Was ist ein guter RMSE für ein Löslichkeitsmodell?
Da experimentelle Löslichkeit zwischen Laboren um etwa 0,6 log streut, ist ein RMSE im Bereich 0,6 bis 0,7 log praktisch das Optimum auf diversen Realdaten. CovaSolv liegt mit 0,64 bis 0,69 genau dort.
Was ist der Unterschied zwischen Scaffold-Split und Random-Split?
Beim Random-Split landen verwandte Moleküle in Training und Test, was die Genauigkeit überschätzt. Beim Scaffold-Split werden ganze Molekülgerüste zurückgehalten, das misst echte Generalisierung auf neue Strukturklassen. CovaSolv berichtet die Scaffold-Zahl.
Schlägt CovaSolv die ESOL-Gleichung?
Ja. Auf dem wässrigen Held-out-Subset erreicht CovaSolv RMSE 0,69 und R² 0,91 gegenüber 0,96 und 0,55 für ESOL (Delaney 2004).
Wie weiß ich, ob ich einer Vorhersage vertrauen kann?
Jede CovaSolv-Vorhersage kommt mit einem kalibrierten Conformal-Intervall und einem Applicability-Domain-Flag, das anzeigt, wann das Modell extrapoliert.
Methodik & Daten
Modell: CovaSolv (XGBoost/LightGBM-Ensemble, 339 Features). Training: 95.633 Messungen aus BigSolDB v2.0 und OChem. Evaluation: Scaffold-Holdout, 5.315 zurückgehaltene Verbindungen (R² 0,920 / RMSE 0,636 / MAE 0,371 / 78,0 % ≤ 0,5 log); wässriges Held-out-Subset für den ESOL-Vergleich (RMSE 0,689 / R² 0,914 / 76,4 % ≤ 0,5 log). Literaturwerte (ESOL, LightGBM 2025, SolTranNet, Solubility Challenge) stammen aus publizierten, abweichenden Test-Sets und sind nur als Größenordnung zu lesen. Daten-Snapshot: 2026-05-21.
CovaSyn MCP
Wissenschaftliche Tools in deinem AI-Workflow.
130+ Funktionen für Pharma, Biotech und Chemie. Free-Tier sofort aktiv.