Gemini 3.5 Flash in der Chemie: von 14 % auf 76 % — warum das günstigste Modell den größten Sprung macht
Gemini 3.5 Flash erreicht ohne Tools nur 14 % bei molekularem Reasoning. Mit CovaSyn-MCP-Anbindung springt dasselbe Modell auf 76 % — ein 5,5×-Lift, der größte aller getesteten Frontier-Modelle. Warum das günstigste Modell am meisten profitiert, was es kostet, und wo der Lift noch nicht perfekt ist.
Oliver Kraft
CovaSyn

Das Wichtigste in Kürze
- Gemini 3.5 Flash erreicht ohne Tools nur 14 % auf molekularen Reasoning-Aufgaben (Atome zählen, Ringe und Stereozentren bestimmen, Scaffolds zerlegen).
- Mit CovaSyn-MCP-Anbindung springt dasselbe Modell auf 76 % — ein 5,5×-Lift, der größte aller getesteten Modelle.
- Count-Aufgaben: 21 % → 87 %. Index-Aufgaben: 6 % → 64 %.
- Bei 36 von 66 Feature/Aufgaben-Kombinationen erreicht Gemini + MCP die volle Trefferquote (100 %).
- Basis: 910 symbolisch verifizierbare Fragen aus dem MolecularIQ-Benchmark (JKU Linz, ICLR 2026), Auswertung ohne LLM-Richter.
Worum es geht
Ein günstiges, schnelles Modell wie Gemini 3.5 Flash ist für viele R&D-Teams die naheliegende Wahl, wenn ein Agent im Hintergrund chemische Strukturen verarbeiten soll: niedrige Kosten pro Aufruf, gute Latenz, breite Verfügbarkeit. Die offene Frage ist nur: rechnet das Modell tatsächlich Chemie — oder rät es?
Wir haben das nicht mit einem selbstgebauten Test geprüft, sondern mit einem unabhängigen, peer-reviewten Benchmark. Und das Ergebnis ist eindeutiger, als wir erwartet hatten.
Wie gut ist Gemini 3.5 Flash in Chemie — ohne Tools?
Kurz gesagt: nicht gut genug für produktive R&D. Über alle Aufgaben hinweg liegt Gemini 3.5 Flash allein bei 13,7 % korrekten Antworten. Das ist kein Vorwurf an das Modell — es ist die erwartbare Grenze eines Sprachmodells, das Moleküle als Token-Strings sieht statt als Graphen.
Zwei Beispiele aus dem Datensatz machen das greifbar:
- Bridgehead-Atome zählen: 0 % korrekt. Das Modell hat keinen verlässlichen Weg, verbrückte Ringsysteme zu erkennen.
- BRICS-Fragmentierung, Stereozentren, kleinster/größter Ringgröße: ebenfalls nahe 0 %.
Genau das sind keine exotischen Aufgaben. Es sind die Bausteine, die in der Medizinalchemie täglich gebraucht werden — und es sind Aufgaben mit einer deterministisch korrekten Antwort. Ein Modell, das sie errät, ist in einem regulierten Workflow nicht einsetzbar.
Was passiert mit CovaSyn MCP?
Sobald Gemini 3.5 Flash über das Model Context Protocol auf die deterministischen CovaSyn-Tools zugreifen kann, kehrt sich das Bild um. Die Gesamt-Trefferquote steigt von 14 % auf 76 %.
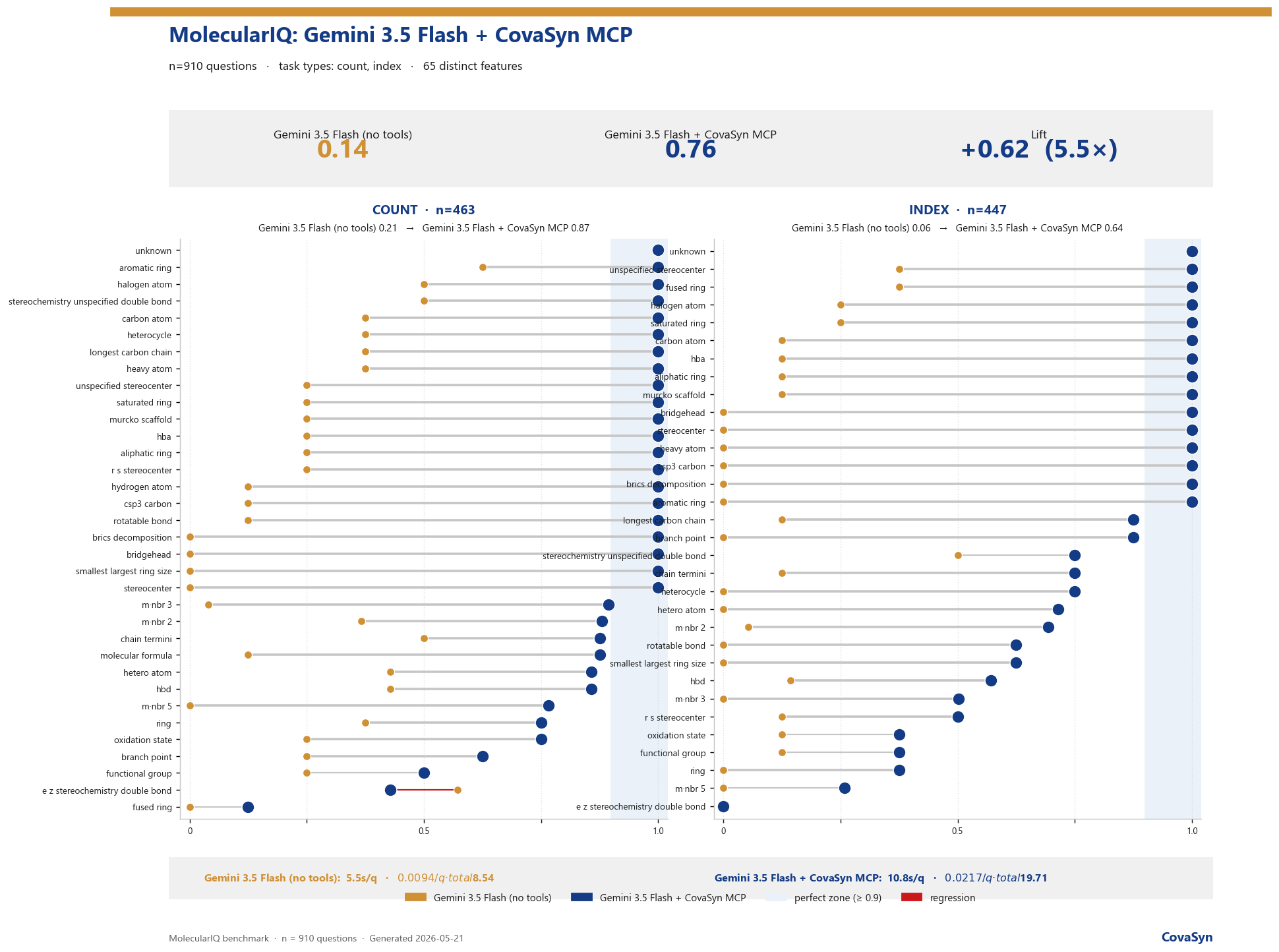
Aufgeschlüsselt nach Aufgaben-Typ:
- Count (n = 463): 21 % → 87 % (+66 pp)
- Index (n = 447): 6 % → 64 % (+58 pp)
- Gesamt (n = 910): 14 % → 76 % (5,5×)
Der Mechanismus ist simpel und genau deshalb robust: Das Modell delegiert die strukturelle Berechnung an ein Werkzeug, das die Antwort rechnet statt sie zu schätzen. Wenn Gemini "zähle die Bridgehead-Atome" an covabasic_analyze weitergibt, "zerlege das Grundgerüst" an covabasic_scaffold_analysis, oder "fragmentiere retrosynthetisch" an covabasic_brics, kommt ein RDKit-verifizierter Wert zurück. Das Sprachmodell muss nur noch korrekt formulieren — nicht mehr korrekt rechnen.
Warum macht das günstigste Modell den größten Sprung?
Das ist die eigentlich interessante Beobachtung. Über alle vier getesteten Frontier-Modelle hinweg gilt: je niedriger die Baseline, desto größer der relative Lift. Gemini 3.5 Flash startet am niedrigsten — und macht mit 5,5× den absolut größten Sprung.
Der Grund ist strukturell, nicht zufällig. Was ein teureres Modell an chemischem "Bauchgefühl" mitbringt, wird wertlos, sobald die Antwort ohnehin deterministisch verifiziert wird. Die strukturelle Verifikation nivelliert die Modell-Unterschiede: Der Engpass verschiebt sich vom Modellwissen zur Tool-Anbindung. Das ist die wichtigste praktische Konsequenz des Benchmarks — der Lift hängt am Werkzeug, nicht am Modell.
Wo der Lift am größten ist
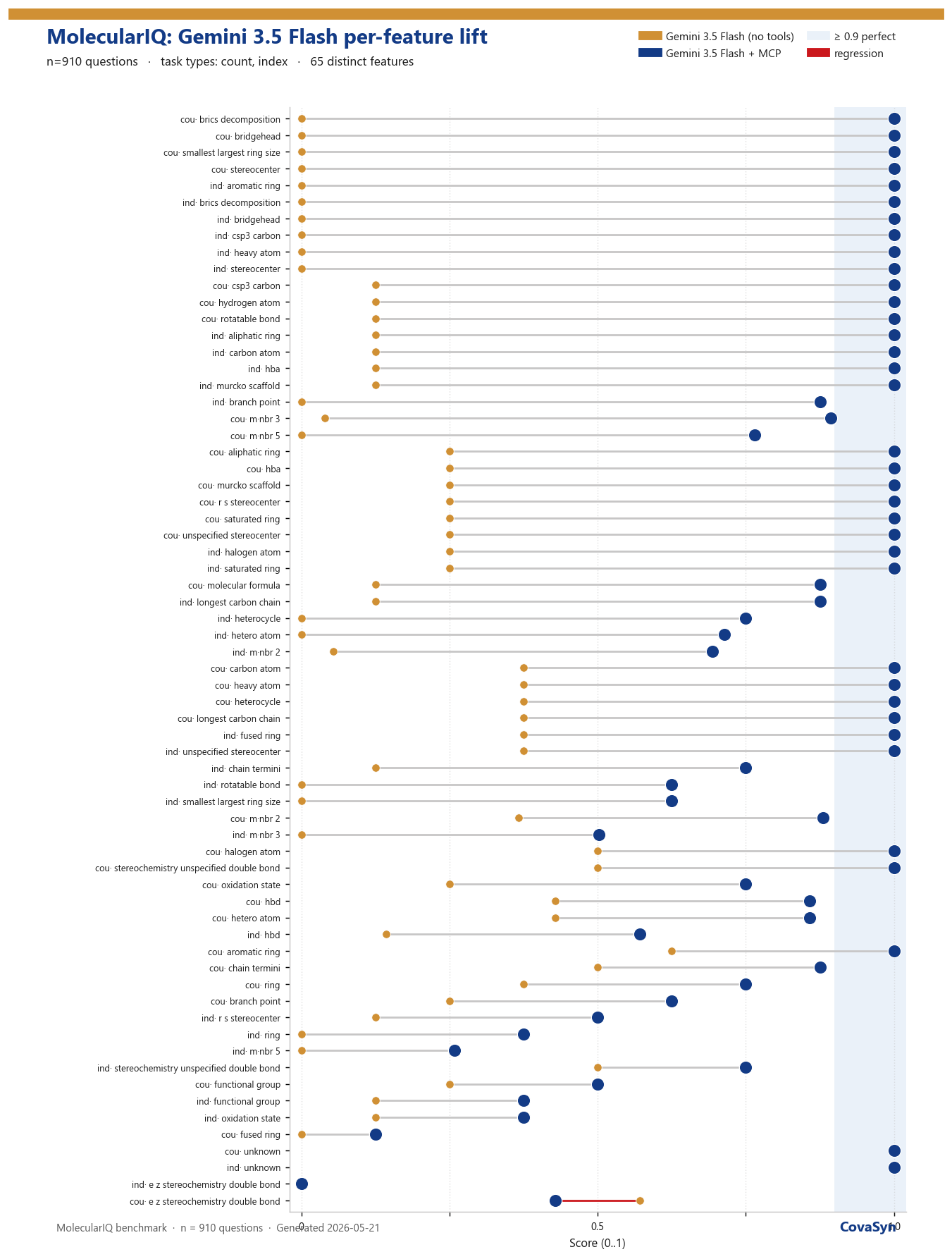
Die spektakulärsten Sprünge sind genau die Aufgaben, an denen das Modell allein vollständig scheitert (0 % → 100 %):
- BRICS-Fragmentierung (Count & Index)
- Bridgehead-Atome
- Stereozentren und R/S-Stereozentren
- csp³-Kohlenstoffe, aromatische Ringe
- kleinste/größte Ringgröße, Murcko-Scaffold
Das Muster ist konsistent: Überall dort, wo die Aufgabe eine exakte graph-theoretische Berechnung verlangt, ist der Effekt am größten. Count-Aufgaben (etwas zählen) profitieren dabei stärker als Index-Aufgaben (eine konkrete Atom-Position bestimmen) — letztere bleiben für jedes Sprachmodell die härtere Nuss, weil sie nicht nur ein Ergebnis, sondern eine korrekte Adressierung im Molekülgraphen verlangen.
Der Kosten-Hebel
Mehr Genauigkeit ist nur die halbe Geschichte. Die andere Hälfte ist, was sie kostet.
- Gemini 3.5 Flash ohne Tools: 0,0094 USD/Frage, 5,5 s/Frage → 14 %
- Gemini 3.5 Flash + CovaSyn MCP: 0,0217 USD/Frage, 10,8 s/Frage → 76 %
Das bedeutet: rund 2,3× Kosten und 2× Latenz für 5,5× Genauigkeit. In absoluten Zahlen reden wir über gut zwei Cent pro Frage — eine Größenordnung, in der die Genauigkeit den Aufpreis trivial macht, sobald die Ausgabe in einem echten R&D-Schritt landet.
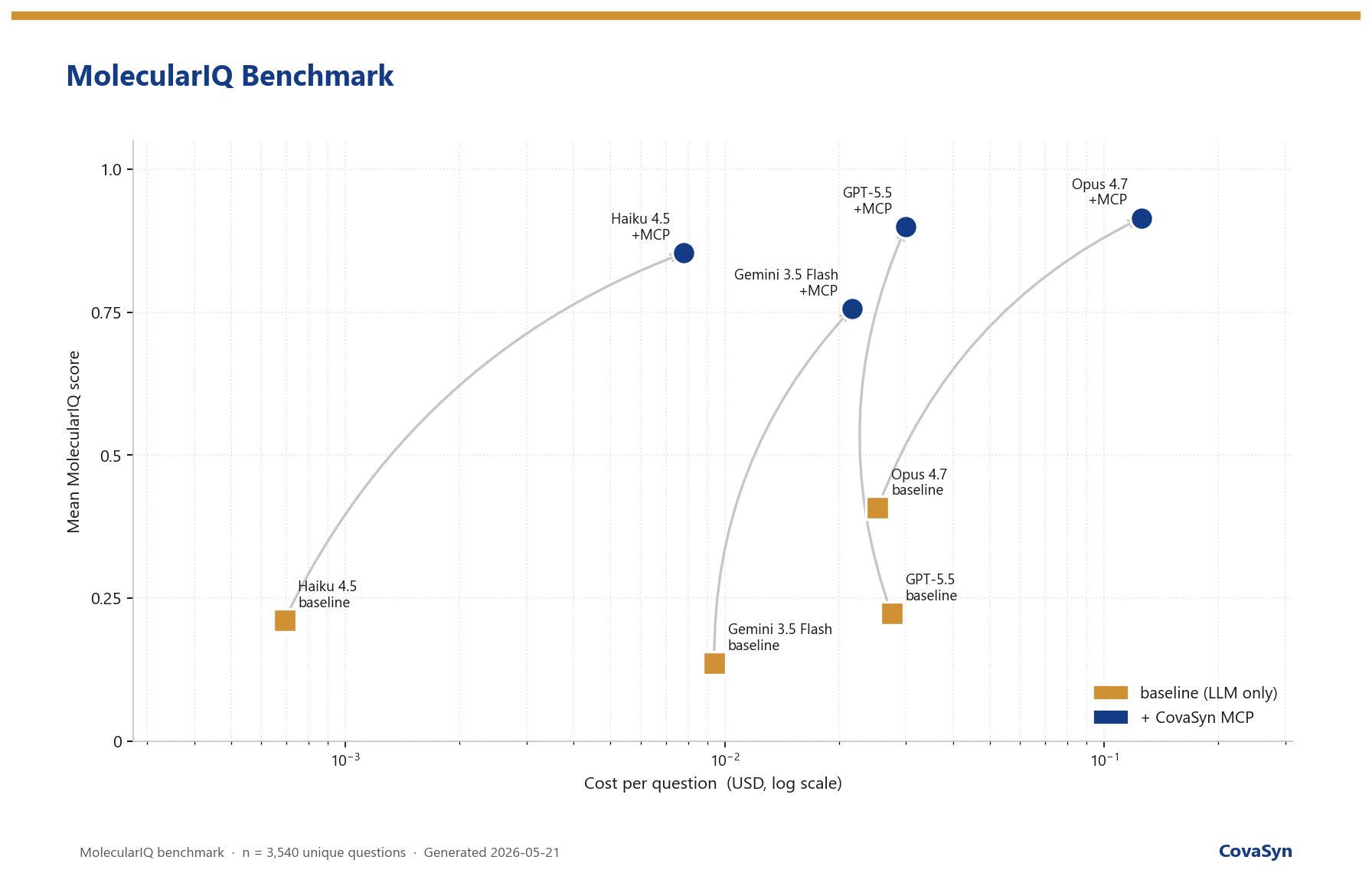
Im Modell-übergreifenden Vergleich verschiebt CovaSyn die gesamte Pareto-Front nach oben. Wer den reinen Kosten-Effizienz-Punkt sucht, landet bei Haiku 4.5 + CovaSyn (≈ 85 % zu sehr niedrigen Kosten pro Frage). Wer auf maximaler Genauigkeit besteht, bei Opus 4.7 + CovaSyn (≈ 92 %). Gemini 3.5 Flash + CovaSyn ist die Wahl für Teams, die ein günstiges, schnelles Modell bereits im Stack haben und es ohne Modellwechsel auf produktives Niveau heben wollen. Den vollständigen Vier-Modell-Vergleich findest du in unserem ICLR-2026-Überblick.
Wo es (noch) nicht perfekt ist
Wir publizieren auch die Lücken, weil eine ehrliche Zahl mehr wert ist als ein blank poliertes Versprechen.
- E/Z-Stereochemie an Doppelbindungen (Count): der einzige Rückschritt im Datensatz — von 57 % auf 43 %. Hier überschreibt das Modell teilweise einen korrekten Tool-Wert mit eigener Logik.
- Mehrfach-Bedingungen beim Indexing (z. B. fünf gleichzeitige Index-Constraints) bleiben mit 26 % die härteste Kategorie.
- Ein Teil der verbleibenden Fehler ist kein Rechen-, sondern ein Übernahme-Problem: Das Tool liefert den richtigen Wert, das Modell ignoriert ihn. Das ist eine Prompt- und Orchestrierungs-Aufgabe, an der wir aktiv arbeiten.
Die vollständige Fehlerverteilung steht offen unter covasyn.com/benchmark.
Was das für AI-Agenten in der Wirkstoffforschung bedeutet
Der breitere Punkt reicht über Gemini hinaus. AI in der Wirkstoffforschung scheitert selten am Sprachmodell und fast immer an der fehlenden Verifikationsschicht: Ein Agent, der ADMET einschätzt, Strukturalerts prüft oder Scaffolds vergleicht, ist nur so vertrauenswürdig wie die deterministischen Werkzeuge unter ihm. Genau diese Schicht liefert CovaSyn über MCP — und der Benchmark zeigt, dass der Effekt modell-unabhängig ist und sich auf das jeweils nächste Frontier-Modell überträgt.
Für regulierte Pharma- und CDMO-Workflows ist das doppelt relevant: Validierungsaufwand hängt an reproduzierbaren Zahlen, und reproduzierbar ist nur, was berechnet statt geschätzt wird.
Selbst nachvollziehen
Im Free-Tier kannst du den Effekt in deinem eigenen Setup prüfen: Account anlegen, API-Key generieren, an deinen Agenten — Claude, ChatGPT, Cursor oder Copilot — hängen. 100 Credits pro Woche sind dabei, ohne Kreditkarte. → CovaSyn MCP ansehen
Häufige Fragen
Wie genau ist Gemini 3.5 Flash bei chemischen Aufgaben?
Ohne Werkzeuge erreicht Gemini 3.5 Flash im MolecularIQ-Benchmark 14 % korrekte Antworten. Mit deterministischer Tool-Anbindung über CovaSyn MCP steigt das auf 76 %.
Warum profitiert Gemini 3.5 Flash stärker als teurere Modelle?
Weil die strukturelle Verifikation die Modell-Unterschiede nivelliert. Je niedriger die Baseline eines Modells, desto größer der relative Lift — Gemini macht mit 5,5× den größten Sprung aller getesteten Modelle.
Was ist CovaSyn MCP?
Eine Sammlung deterministischer Chemie-Werkzeuge (RDKit-gestützt), die ein AI-Agent über das Model Context Protocol aufruft — vom Atom-Zählen über Scaffold-Zerlegung bis zu Stabilität, ADMET und Analytik.
Welches LLM eignet sich am besten für Cheminformatik?
Für reine Kosten-Effizienz Haiku 4.5 + CovaSyn, für maximale Genauigkeit Opus 4.7 + CovaSyn. Entscheidend ist nicht das Modell, sondern die Tool-Anbindung — der Lift überträgt sich auf jedes Frontier-Modell.
Ist der Benchmark unabhängig?
Ja. MolecularIQ stammt vom Institut für Machine Learning der JKU Linz (ICLR 2026). Die Bewertung läuft ohne LLM-Richter — nur die vollständige Übereinstimmung mit der Ground Truth zählt.
Quelle & Methodik
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026, arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Verwendet: Test-Split, symbolisch verifizierbare Frage-Typen (Count + Index), n = 910 für Gemini 3.5 Flash. Daten-Snapshot: 2026-05-21.
CovaSyn MCP
Wissenschaftliche Tools in deinem AI-Workflow.
130+ Funktionen für Pharma, Biotech und Chemie. Free-Tier sofort aktiv.