ICLR 2026 Benchmark
On the peer-reviewed MolecularIQ benchmark, four frontier LLMs score 14 to 41 percent on chemical structure analysis. With CovaSyn MCP attached, the same models reach 76 to 92 percent. Three of the four land at 85 to 92 %; the cheapest model (Gemini 3.5 Flash) at 76 %. Here are the numbers, and what they don't show.
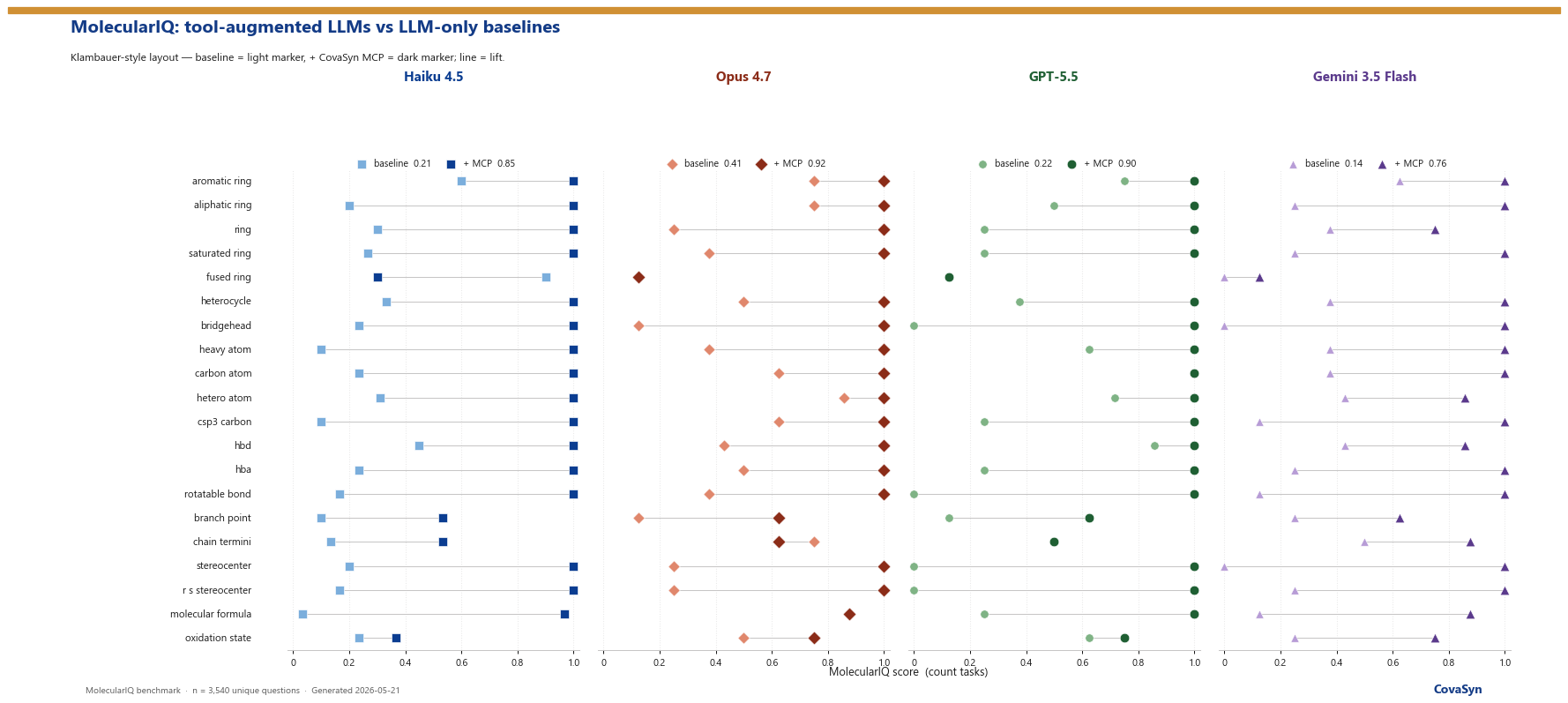
Top-line numbers
| Model | Baseline | + CovaSyn MCP | Δ | Lift |
|---|---|---|---|---|
| Claude Haiku 4.5 | 21.18 % | 85.38 % | +64.20 pp | 4.03× |
| Claude Opus 4.7 | 40.75 % | 91.51 % | +50.76 pp | 2.25× |
| OpenAI GPT-5.5 | 22.29 % | 89.92 % | +67.63 pp | 4.03× |
| Gemini 3.5 Flash | 13.68 % | 75.66 % | +61.98 pp | 5.53× |
What this means in cost terms
Frontier models are expensive. With CovaSyn, you can often run the cheaper model without giving up accuracy.
| Configuration | Accuracy | $/question | Latency |
|---|---|---|---|
| Haiku 4.5 baseline | 21.18 % | $0.00069 | 2.1 s |
| Haiku 4.5 + CovaSyn MCP | 85.38 % | $0.00781 | 5.8 s |
| Opus 4.7 baseline | 40.75 % | $0.02529 | 5.1 s |
| Opus 4.7 + CovaSyn MCP | 91.51 % | $0.12536 | 7.4 s |
| GPT-5.5 baseline | 22.29 % | $0.02750 | 7.9 s |
| GPT-5.5 + CovaSyn MCP | 89.92 % | $0.03005 | 9.4 s |
| Gemini 3.5 Flash baseline | 13.68 % | $0.00940 | 5.5 s |
| Gemini 3.5 Flash + CovaSyn MCP | 75.66 % | $0.02170 | 10.8 s |
The sharp claim:
Haiku 4.5 + CovaSyn is the cost-efficiency sweet spot: 2.1× the accuracy of Opus 4.7 baseline at 32 % of the cost, and 16× cheaper than Opus 4.7 + CovaSyn while giving up only 6 pp accuracy. Gemini 3.5 Flash + CovaSyn delivers the largest relative lift (5.53× from 13.7 % to 75.7 %) at roughly 2.3× baseline cost and 2× baseline latency, the right option for teams already running Gemini in their stack.




Where CovaSyn lifts hardest
Mean accuracy lift across 8 question categories (averaged across Haiku 4.5, Opus 4.7 and GPT-5.5; Gemini 3.5 Flash data with the next snapshot):
| Category | Baseline | + CovaSyn MCP | Δ |
|---|---|---|---|
| Scaffold & fragments | 18.0 % | 86.5 % | +68.4 pp |
| Rings & topology | 29.4 % | 93.2 % | +63.8 pp |
| Bonds & chains | 17.6 % | 80.9 % | +63.3 pp |
| Multi-feature questions | 27.3 % | 88.4 % | +61.1 pp |
| Atom & formula counts | 38.7 % | 98.3 % | +59.7 pp |
| Stereochemistry | 28.7 % | 86.0 % | +57.4 pp |
| Electronics & H-bonds | 31.2 % | 81.5 % | +50.3 pp |






Methodology
Benchmark
MolecularIQ by Bartmann et al., ICLR 2026 (arXiv:2601.15279). 3,540 tasks, 65 features, three complexity bins. Dataset public on HuggingFace.
Models
Claude Haiku 4.5, Claude Opus 4.7, OpenAI GPT-5.5 and Gemini 3.5 Flash. Each tested with and without CovaSyn MCP.
Verification
Symbolic, no LLM judges. Score only when the full answer matches ground truth.
Tools
Five chemistry primitives from the CovaBasicChem suite. Cheminformatics operations, deterministic, validated.
Volume
12,540 model responses in total. Haiku ran the full test split, Opus, GPT-5.5 and Gemini on a stratified sample of 910 questions each.
Where we still improve
We do not hit 100 %, and we do not want to hide that. Here is how the remaining gap breaks down and where you would look closer for your own validation.
| Category | Haiku + MCP | Opus + MCP | GPT-5.5 + MCP | Gemini + MCP |
|---|---|---|---|---|
| Correct | 73.2 % | 83.0 % | 83.6 % | 72.3 % |
| Tool result discarded | 21.6 % | 14.5 % | 10.9 % | 6.9 % |
| Tool value off | 4.8 % | 2.2 % | 1.4 % | 0.7 % |
| Format error | 0.2 % | 0.2 % | 4.1 % | 20.1 % |
Most of the remaining gap sits between tool and model, not in the tool itself. We address that continuously.
Citation
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026 (poster, Pavilion 4 · P4-#5202, 24 Apr 2026), arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Dataset: huggingface.co/datasets/ml-jku/moleculariq-v0.0. Data snapshot: 2026-05-17.
Go deeper
In-depth analysis with methodology, implications and FAQ
About 12 minutes of reading. Background on model choice, cost Pareto in detail, GxP implications, FAQs. →
Test it yourself
The tools that produced this lift are available in every CovaSyn account, including the free tier with 100 credits per week.