Gemini 3.5 Flash on chemistry: from 14 % to 76 % — why the cheapest model makes the biggest jump
Gemini 3.5 Flash reaches just 14 % on molecular reasoning without tools. Attach CovaSyn MCP and the same model jumps to 76 % — a 5.5× lift, the largest of all tested frontier models. Why the cheapest model benefits most, what it costs, and where the lift is not yet perfect.
Oliver Kraft
CovaSyn

Key takeaways
- Gemini 3.5 Flash reaches only 14 % on molecular reasoning tasks without tools (counting atoms, identifying rings and stereocenters, decomposing scaffolds).
- With CovaSyn MCP attached, the same model jumps to 76 % — a 5.5× lift, the largest of all tested models.
- Count tasks: 21 % → 87 %. Index tasks: 6 % → 64 %.
- On 36 of 66 feature/task combinations Gemini + MCP hits a perfect score (100 %).
- Basis: 910 symbolically verifiable questions from the MolecularIQ benchmark (JKU Linz, ICLR 2026), scored without LLM judges.
What this is about
A cheap, fast model like Gemini 3.5 Flash is the obvious pick for many R&D teams when an agent runs chemistry workflows in the background: low cost per call, good latency, broad availability. The open question is: does the model actually compute chemistry — or guess?
We did not test this with a homegrown benchmark, we used an independent, peer-reviewed one. The result is more clear-cut than we expected.
How good is Gemini 3.5 Flash on chemistry — without tools?
Short version: not good enough for production R&D. Across all tasks Gemini 3.5 Flash alone lands at 13.7 % correct answers. That is not a knock on the model — it is the expected ceiling for a language model that sees molecules as token strings rather than graphs.
Two concrete examples from the dataset:
- Counting bridgehead atoms: 0 % correct. The model has no reliable way to identify bridged ring systems.
- BRICS fragmentation, stereocenters, smallest/largest ring size: also near 0 %.
These are not exotic tasks. They are the building blocks of medicinal chemistry, with one deterministically correct answer. A model that guesses them is not usable in a regulated workflow.
What happens with CovaSyn MCP?
Once Gemini 3.5 Flash can call the deterministic CovaSyn tools through the Model Context Protocol, the picture reverses. Total accuracy goes from 14 % to 76 %.
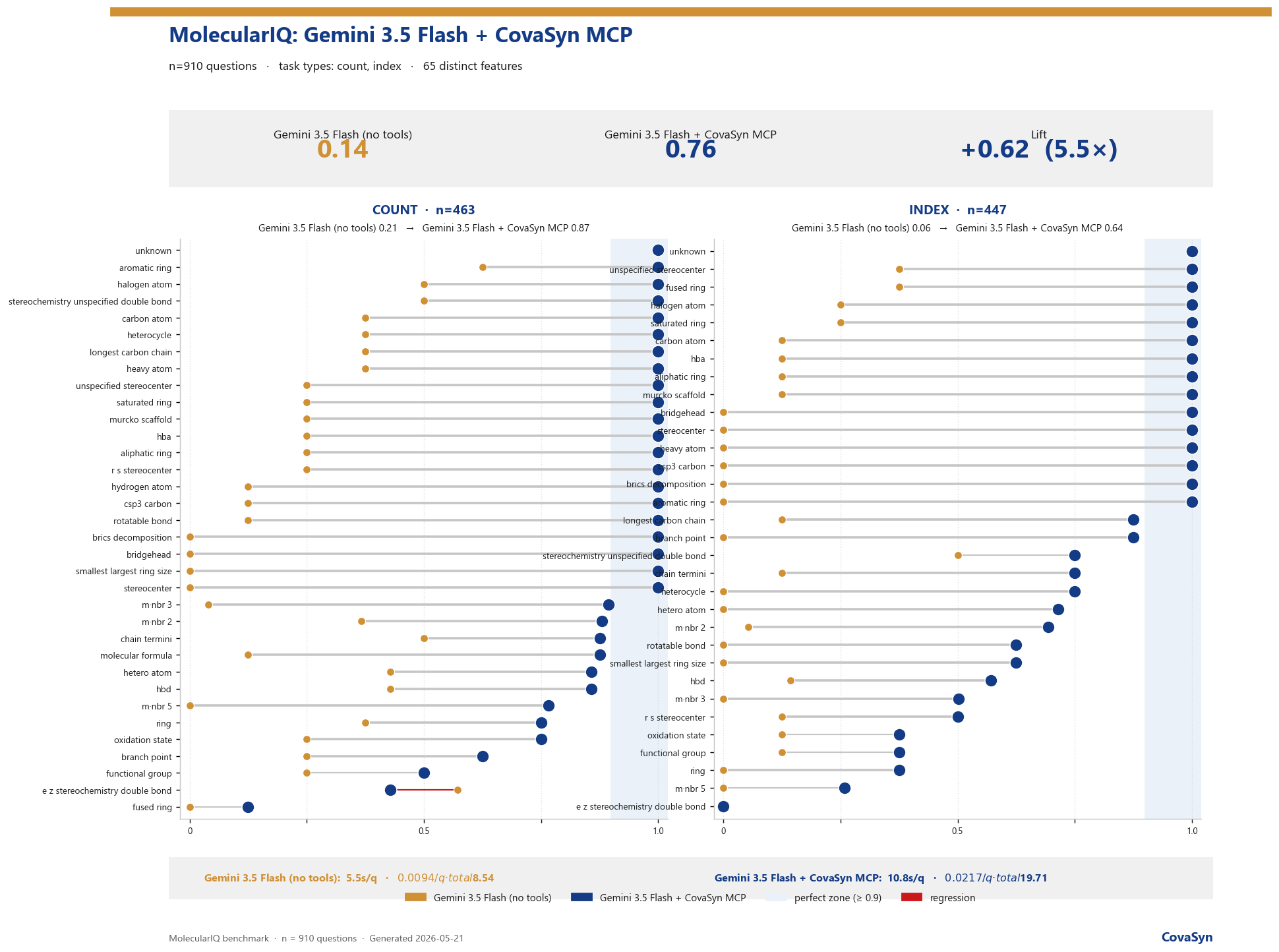
By task type:
- Count (n = 463): 21 % → 87 % (+66 pp)
- Index (n = 447): 6 % → 64 % (+58 pp)
- Overall (n = 910): 14 % → 76 % (5.5×)
The mechanism is simple and that is exactly why it holds. The model delegates structural computation to a tool that calculates the answer instead of estimating it. When Gemini hands "count the bridgehead atoms" to covabasic_analyze, "extract the scaffold" to covabasic_scaffold_analysis, or "fragment retrosynthetically" to covabasic_brics, an RDKit-verified value comes back. The language model only needs to phrase it correctly — it no longer needs to compute it correctly.
Why does the cheapest model make the biggest jump?
This is the real observation. Across all four tested frontier models the pattern holds: the lower the baseline, the larger the relative lift. Gemini 3.5 Flash starts lowest — and posts the largest absolute lift at 5.5×.
The reason is structural, not coincidental. Whatever chemical "intuition" a more expensive model brings becomes worthless once the answer is deterministically verified anyway. Structural verification flattens model differences: the bottleneck shifts from model knowledge to tool integration. That is the most important practical consequence of the benchmark — the lift hangs on the tooling, not the model.
Where the lift is biggest
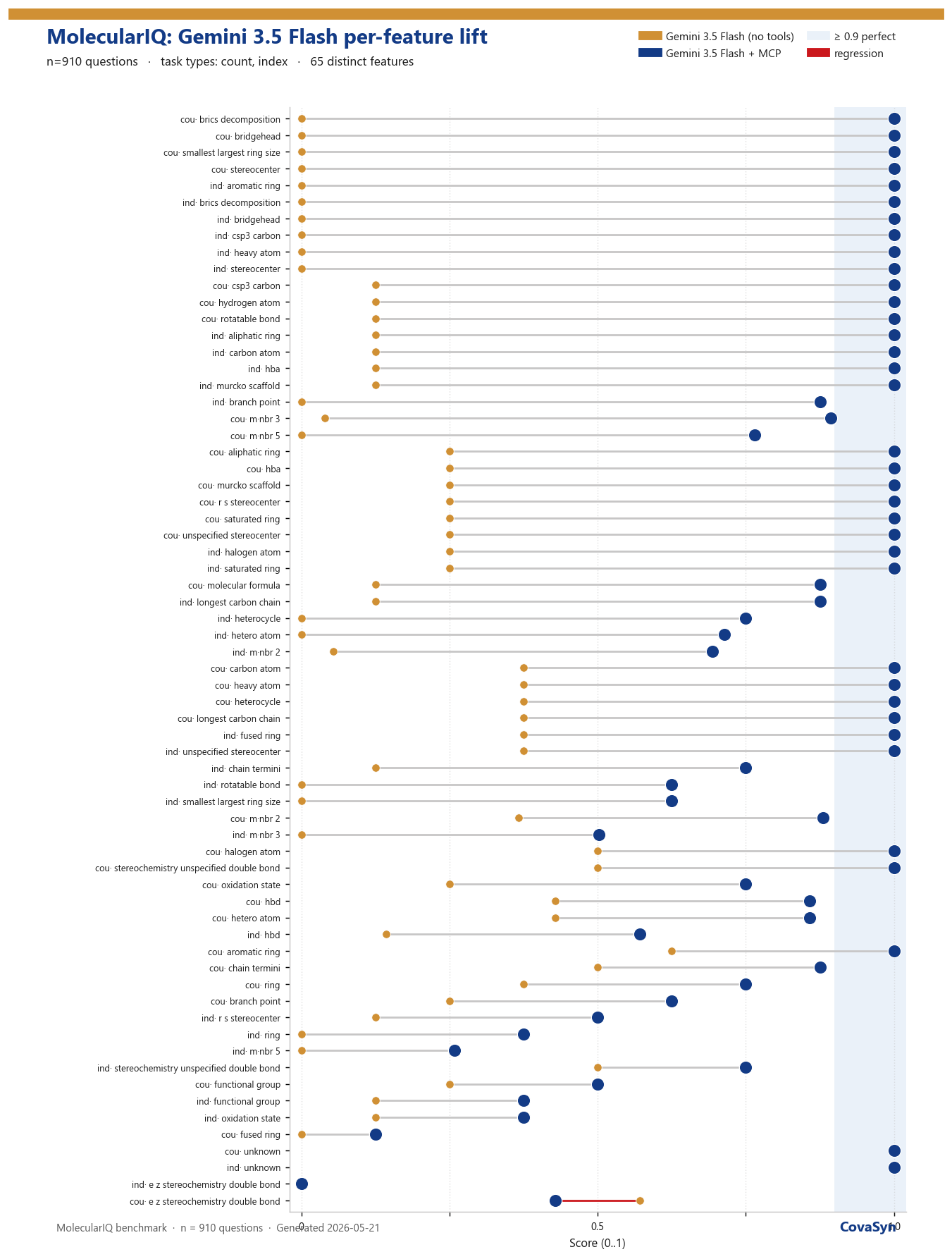
The most striking jumps are exactly the tasks where the model alone fails completely (0 % → 100 %):
- BRICS fragmentation (count and index)
- Bridgehead atoms
- Stereocenters and R/S stereocenters
- csp³ carbons, aromatic rings
- smallest/largest ring size, Murcko scaffold
The pattern is consistent: anywhere a task requires an exact graph-theoretic computation, the effect is largest. Count tasks (counting something) benefit more than index tasks (identifying a specific atom position) — the latter remains the harder nut for any language model, because it requires not just a result but a correct addressing inside the molecular graph.
The cost lever
Higher accuracy is only half the story. What it costs is the other half.
- Gemini 3.5 Flash without tools: 0.0094 USD/question, 5.5 s/question → 14 %
- Gemini 3.5 Flash + CovaSyn MCP: 0.0217 USD/question, 10.8 s/question → 76 %
That is roughly 2.3× cost and 2× latency for 5.5× accuracy. In absolute numbers we are talking about two cents per question — at this magnitude the accuracy makes the markup trivial as soon as the output feeds into a real R&D step.
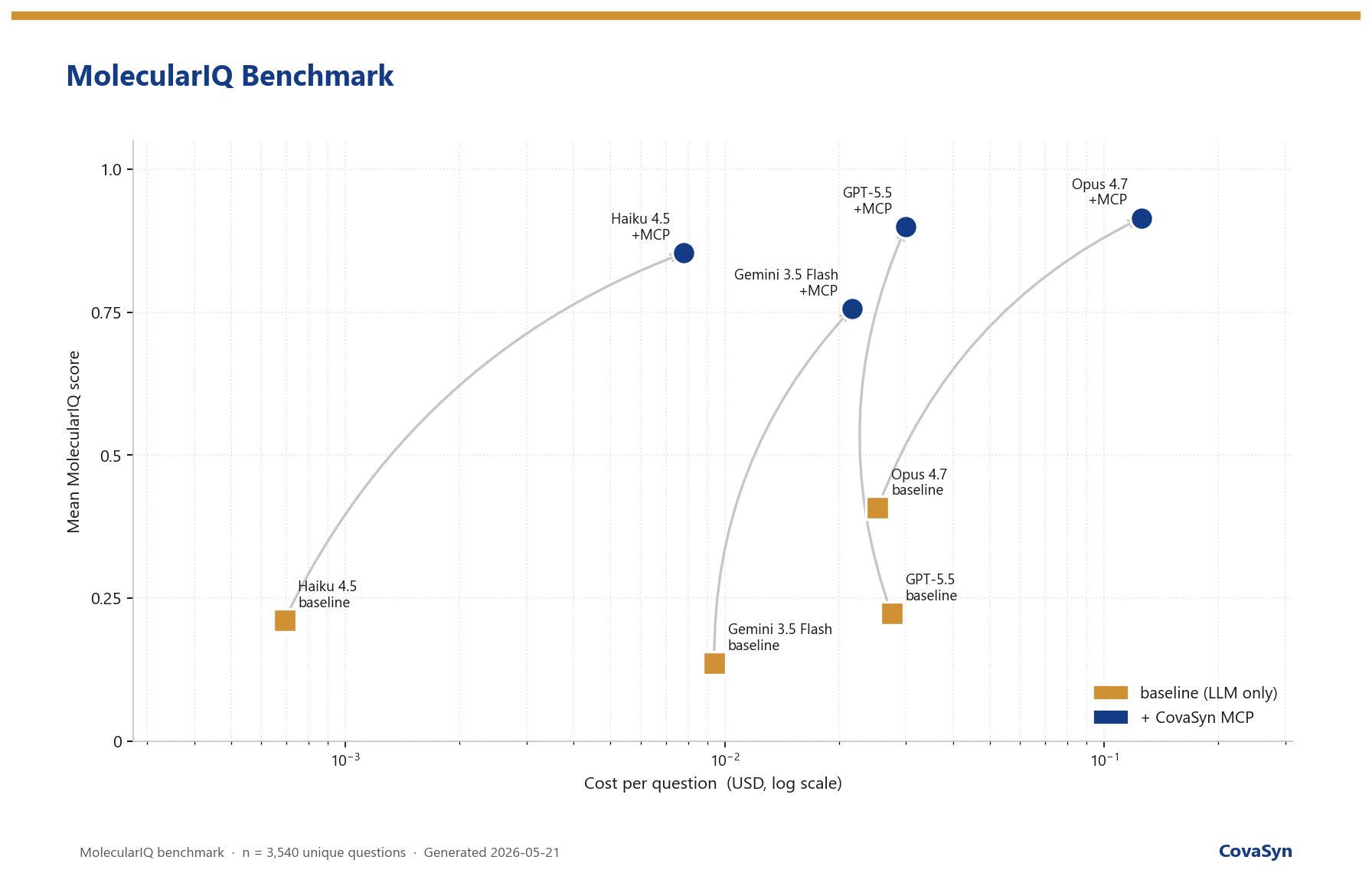
In the cross-model comparison CovaSyn shifts the entire Pareto frontier upward. The pure cost-efficiency sweet spot is Haiku 4.5 + CovaSyn (≈ 85 % at very low cost per question). For maximum accuracy, it is Opus 4.7 + CovaSyn (≈ 92 %). Gemini 3.5 Flash + CovaSyn is the right choice for teams that already have a cheap, fast model in their stack and want to lift it to production grade without switching models. The full four-model comparison sits in our ICLR 2026 overview.
Where it is (not yet) perfect
We publish the gaps too, because an honest number is worth more than a polished promise.
- E/Z stereochemistry on double bonds (count): the only regression in the dataset — from 57 % to 43 %. The model partially overrides a correct tool value with its own logic.
- Multi-condition indexing (e.g. five simultaneous index constraints) remains the hardest category at 26 %.
- Part of the remaining error is not a computation problem but an adoption problem: the tool returns the right value, the model ignores it. That is a prompt and orchestration job we are actively working on.
The full error distribution is open at covasyn.com/benchmark.
What this means for AI agents in drug discovery
The broader point reaches beyond Gemini. AI in drug discovery rarely fails at the language model and almost always at the missing verification layer: an agent that scores ADMET, checks structural alerts or compares scaffolds is only as trustworthy as the deterministic tools underneath. That layer is exactly what CovaSyn delivers via MCP — and the benchmark shows the effect is model-independent and carries over to the next frontier model.
For regulated pharma and CDMO workflows that is doubly relevant: validation effort hangs on reproducible numbers, and only what is computed (not estimated) is reproducible.
See it for yourself
The free tier lets you verify the effect in your own setup: create an account, generate an API key, attach it to your agent — Claude, ChatGPT, Cursor or Copilot. 100 credits per week included, no credit card. → See CovaSyn MCP
FAQ
How accurate is Gemini 3.5 Flash on chemistry tasks?
Without tools, Gemini 3.5 Flash hits 14 % correct answers on the MolecularIQ benchmark. With deterministic tool calls through CovaSyn MCP that rises to 76 %.
Why does Gemini 3.5 Flash benefit more than more expensive models?
Because structural verification flattens model differences. The lower the baseline of a model, the larger the relative lift — Gemini posts the largest jump of all tested models at 5.5×.
What is CovaSyn MCP?
A collection of deterministic chemistry tools (RDKit-backed) that an AI agent calls through the Model Context Protocol — from atom counting and scaffold decomposition to stability, ADMET and analytics.
Which LLM is best for cheminformatics?
Haiku 4.5 + CovaSyn for cost-efficiency, Opus 4.7 + CovaSyn for maximum accuracy. The decisive factor is not the model but the tool integration — the lift carries over to any frontier model.
Is the benchmark independent?
Yes. MolecularIQ comes from the Institute for Machine Learning at JKU Linz (ICLR 2026). Scoring runs without LLM judges — only a full match against ground truth counts.
Source and methodology
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026, arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Used: test split, symbolically verifiable question types (count + index), n = 910 for Gemini 3.5 Flash. Data snapshot: 2026-05-21.
CovaSyn MCP
Scientific tools in your AI workflow.
130+ functions for pharma, biotech and chemistry. Free tier instantly active.